Dostupnost IT usluga je od velike važnosti. Kada usluge koje zahtijeva kupac nisu dostupne, on će biti nezadovoljan. Zašto bi korisnik trebao platiti uslugu koja zapravo nije dostupna kada mu je potrebna? Zbog toga je dogovorena mjera dostupnosti usluge često uključena u KPI.
IT osoblje uložilo je mnogo truda kako bi bili sigurni da je zadani cilj postignut te u izvješćima korisnicima prikazuju brojeve koji to potvrđuju. Obično IT tvrtke za to koriste postotke, na primjer 99,999%. Nažalost, to često znači da se usredotočuju samo na postotke i gube iz vida svoju pravu svrhu - isporučiti vrijednost kupcu.
Problem s postotkom dostupnosti
Jedan od najjednostavnijih načina izračuna dostupnosti temelji se na dva dijela. Sami dogovarate vremenske intervale u kojima bi usluga trebala biti dostupna izvještajno razdoblje. Ovo je dogovoreno vrijeme usluge (AST). Tijekom ovog razdoblja mjerite zastoj (DT). Oduzmite vrijeme zastoja od dogovorenog vremena dostupnosti usluge i pretvorite to u postotak.
Ako je AST 100 sati, a prekid rada 2 sata, dostupnost će biti:

Problem je u tome što, iako je ovaj izračun prilično jednostavan, kao i prikupljanje podataka za njega, zapravo nije jasno koji točno pokazatelj predstavlja brojka koju ste dobili kao rezultat izračuna. O ovome ću govoriti malo kasnije.
Još gore, sa stajališta kupca, možete komunicirati da ste postigli dogovorene ciljeve, ostavljajući kupca potpuno nezadovoljnim.
Izvješće o značajnoj dostupnosti trebalo bi se temeljiti na mjerenjima koja opisuju stvari koje kupca zanimaju, kao što je mogućnost slanja i primanja e-pošte ili podizanja gotovine s bankomata, a ukupni postotak očito ne može.
Postavljanje ciljeva pristupačnosti
Ako želite mjeriti, dokumentirati i izvješćivati o dostupnosti na način koji je koristan vašoj organizaciji i vašim klijentima, trebate učiniti dvije stvari. Prvo definirajte kontekst i pojačajte značenje "pristupačnosti" za vas i vaše klijente. Da biste to učinili, morate razgovarati s njima.
Drugo, morate pažljivo razmisliti o nizu praktičnih pitanja: što ćete mjeriti, kako ćete prikupljati podatke, kako ćete dokumentirati i izvješćivati o rezultatima.
Komunikacija s kupcima
Prije nego što poduzmete bilo kakvu radnju, morate razumjeti što je važno vašim kupcima i kakav će učinak na njih imati gubitak dostupnosti. To će vam omogućiti da postavite realne ciljeve koji uzimaju u obzir tehnološka, proračunska i kadrovska ograničenja.
Ali što biste točno trebali reći svojim kupcima? Izvrsno Polazna točka jer razgovor može postati utjecaj zastoja. U nastavku je pet pitanja koja biste trebali postaviti:
- Koje poslovne funkcije su ključne i imaju najveći prioritet za zaštitu od zastoja?
- Kako zastoji utječu na poslovanje?
- Kako učestalost zastoja utječe na poslovanje?
- Kakav utjecaj ima prekid rada na organizacijski učinak?
- Kao ove prisilni zastoj percipiraju klijenti organizacije?
Kritične poslovne funkcije
Većina IT usluga podržava više poslovnih procesa, od kojih su neki kritični, a drugi manje važni. Na primjer, bankomat može podržavati izdavanje gotovine i ispis čekova. Sposobnost raspodjele gotovine presudno, dok nemogućnost ispisa čeka ima puno manji utjecaj.
Morate razgovarati s kupcima i utvrditi koliko su različite značajke važne za poslovanje. Možete izraditi tablicu koja navodi poslovne implikacije zastoja za svaku od ovih funkcija. Primjer:
Tablica 1 - Važnost usluga u postocima
NB: Brojevi ne smiju iznositi 100%
Iz ove tabele se vidi da ovu uslugu uopće nije važno ako nije moguće slati i primati e-poštu, a njegova se vrijednost smanjuje na pola normalne razine ako se javne mape ne mogu čitati. To govori IT-u da se usredotoči na kvalitetu usluge pošte.
Trajanje i učestalost zastoja
Morate saznati kako na klijentovo poslovanje utječe učestalost i trajanje zastoja.
Već sam spomenuo da postotak dostupnosti možda neće biti dovoljan. Kada usluga koja bi trebala biti dostupna 100 sati ima 98% dostupnosti, to znači da je došlo do dva sata zastoja. Ali to može značiti ili jedan dvosatni incident ili nekoliko kraćih. Relativni učinak jednog dugog incidenta ili niza kratkih incidenata varirat će ovisno o prirodi poslovanja i poslovnih procesa.
Na primjer, naplata koja traje dva dana i mora se ponovno pokrenuti nakon bilo kakvog kvara bit će ozbiljno pogođena svakim kratkim prekidom, ali jedan prisilni prekid koji traje dugo može napraviti puno manju razliku. S druge strane, jednominutni prekid ne mora ni na koji način utjecati na rad online trgovine, ali nakon dva sata može dovesti do značajnog gubitka kupaca. Nakon što steknete ideju o vjerojatnom utjecaju zastoja na vaše poslovanje, možete stvoriti mnogo više učinkovitu infrastrukturu, aplikacije i procese koji stvarno pomažu kupcu.
Evo primjera kako se dostupnost može mjeriti i dokumentirati kako bi se odrazila činjenica da utjecaj zastoja varira:
Tablica 2 - Trajanje putovanja i najveća učestalost
Ako koristite takvu tablicu kada s klijentima razgovarate o učestalosti i trajanju zastoja, ti će brojevi vjerojatno biti mnogo korisniji od postotka dostupnosti, a zasigurno će važniji vašim kupcima.
Zastoj i performanse
Spomenuo sam da postotak dostupnosti nije baš koristan za komunikaciju s korisnicima o učestalosti i trajanju zastoja. S druge strane, kada raspravljate o utjecaju zastoja na izvedbu, postoci mogu biti vrlo korisni.
Većina incidenata ne uzrokuje potpuni gubitak usluge za sve korisnike. Neki korisnici možda neće biti pogođeni dok su drugi potpuno onemogućeni. Možda postoji samo jedan korisnik s pokvarenim računalom koji ne može pristupiti niti jednoj usluzi. Mogli biste to čak klasificirati kao 100% gubitak usluge, ali to bi bilo potpuno nedostižan cilj za IT i ne može biti pravedna mjera pristupačnosti.
S druge strane, možete reći da je usluga dostupna sve dok joj netko drugi može pristupiti. Međutim, nije potrebno puno mašte da se shvati kako bi se korisnici osjećali da je usluga navedena kao dostupna kada je mnogi ljudi jednostavno ne mogu koristiti.
Jedan od načina za određivanje utjecaja je izračunavanje postotka izgubljenih korisničkih minuta. Uraditi ovo:
- Izračunajte potencijalne korisničke minute. Ovo je ukupan broj korisnika koji rade po jedinici vremena. Na primjer, ako imate 10 zaposlenika koji rade 8 sati, tada je PotentialUserMinutes 10 x 8 x 60 = 4800
- Izračunajte UserOutageMinutes. Ovo je ukupan broj korisnika koji su bili nesposobni za rad pomnožen s vremenom kada su bili nesposobni za rad. Na primjer, ako je incident spriječio 5 zaposlenika da rade 10 minuta, tada je UserOutageMinutes 50.
- Izračunajte postotak dostupnosti pomoću formule vrlo slične onoj koju smo vidjeli ranije.
U gornjem primjeru dobili smo sljedeću dostupnost:

Možete koristiti istu metodologiju za izračunavanje utjecaja izgubljene dostupnosti VoIP-a u pozivnom centru u smislu PotentialAgentPhoneMinutes i LostAgentPhoneMinutes; za aplikacije koje se bave transakcijama ili proizvodnjom, možete koristiti sličan pristup za kvantificiranje poslovnog utjecaja incidenta. Uspoređujete broj transakcija koje bi se očekivale bez zastoja u odnosu na broj stvarnih transakcija ili količinu proizvodnje koja se očekivala u odnosu na stvarnu.
Mjerenje dostupnosti i izvješćivanje
Nakon što ste se dogovorili i dokumentirali ciljeve pristupačnosti, trebate razmisliti o praktičnim aspektima kako možete mjeriti i izvješćivati o pristupačnosti. Na primjer:
- Što ćete mjeriti?
- Kako ćete prikupljati podatke?
- Kako ćete dokumentirati i prenijeti svoja otkrića?
Što ste mjerilijabiti
Vrlo je važno mjeriti i izvješćivati o dostupnosti u istim uvjetima koji definiraju ciljeve dogovorene s korisnicima i koji se temelje na zajedničkom razumijevanju onoga što je zapravo pristupačnost za korisnike. Ciljevi bi mu trebali imati smisla i osigurati da su IT napori usmjereni na podršku njegovom poslovanju.
Obično su ti ciljevi dio sporazuma o razini usluge (SLA) između IT-a i korisnika, ali morate paziti da brojevi iz SLA ne postanu vaš cilj. Vaš pravi cilj je pružiti usluge koje ispunjavaju očekivanja vaših kupaca.
Kako prikupiti podatke
Postoji mnogo različitih načina prikupljanja podataka o dostupnosti IT usluga. Neki od njih su jednostavni, ali ne baš precizni, neki su prilično skupi. Možete koristiti samo jedan pristup ili kombinirati nekoliko njih za izradu vlastitih izvješća.
Prikupljanje podataka u tehničkoj podršci
Jedan od načina prikupljanja podataka o dostupnosti je putem službe za pomoć. U pravilu, servisno osoblje određuje utjecaj i trajanje svakog incidenta na poslovanje, jer je to dio upravljanja incidentom. Ti bi se podaci mogli koristiti za određivanje trajanja incidenata i broja pogođenih korisnika.
Ovaj pristup je obično prilično jeftin. Međutim, to može dovesti do sporova o točnosti podataka o dostupnosti.
Mjerenje infrastrukture i dostupnosti aplikacija
Ovaj pristup uključuje skup alata za sve komponente potrebne za pružanje usluge i izračun dostupnosti na temelju razumijevanja načina na koji svaka komponenta doprinosi.
Može biti vrlo učinkovit, ali može propustiti male padove. Na primjer, manja oštećenja baze podataka mogu spriječiti neke korisnike u obavljanju određenih vrsta transakcija. Ova metoda također može propustiti utjecaj uobičajenih komponenti, na primjer, jedan od mojih klijenata redovito nije radio E-mail zbog nepouzdanih DHCP poslužitelja u njihovom sjedištu, ali IT to nije zabilježio kao prekid rada e-pošte.
Fiktivni kupci
Neke tvrtke koriste lažne kupce za slanje poznatih transakcija s određenih točaka na mreži radi testiranja dostupnosti.
Zapravo, ovo je mjerenje end-to-end dostupnosti. Ovisno o veličini i složenosti mreže, ovaj pristup može biti prilično skup za implementaciju, a prijavljuje samo dostupnost od određenih lažnih korisnika. To znači da se mali kvarovi mogu propustiti, na primjer, ako je incident uzrokovao neispravan rad određenog web preglednika, dok lažni korisnik koristi drugi preglednik.
Alati koji podržavaju ovo prikupljanje podataka također često izvješćuju o učinkovitosti i dostupnosti usluge, što može biti koristan dodatak.
Razvoj aplikacija
Neke tvrtke dodaju svojim aplikacijama poseban kod za praćenje dostupnosti s kraja na kraj. To će pomoći da se realno izmjeri end-to-end dostupnost usluga, pod uvjetom da je ovaj cilj postavljen u vrijeme razvoja aplikacije. Ova dorada u pravilu uključuje kod u klijentskoj aplikaciji iu poslužiteljskom dijelu.
Ako se dobro implementira, ne samo da može prikupljati podatke o dostupnosti, već i pomoći u točnom određivanju gdje se dogodio kvar, što može poboljšati dostupnost smanjenjem vremena potrebnog za rješavanje incidenata.
Kako dokumentirati i prenijeti svoja otkrića
Nakon što prikupite podatke o dostupnosti, morate razmisliti o tome kako rezultate prenijeti svojim klijentima.
Planirajte zastoje
Jedan aspekt mjerenja dostupnosti i izvješćivanja koji se često zanemaruje je zastoj. Ako ne uzmete u obzir planirani prekid rada prilikom dizajniranja izvješća o dostupnosti, riskirate uključivanje mjernih podataka koji nisu istiniti.
Postoji nekoliko načina da osigurate da planirani prekid rada ne napuha statistiku. Jedan je imati planirano vrijeme prekida rada za određeno vrijeme koje nije uključeno u izračun dostupnosti. Drugi je dodijeliti planirano vrijeme zastoja. Na primjer, neke organizacije možda neće uzeti u obzir ispade predviđene za budućnost mjesec dana unaprijed.
Bez obzira na to što odlučite učiniti, važno je da vaš SLA jasno definira kako će se planirani prekid rada računati.
Ugovor o obračunskom razdoblju
Ranije sam govorio o ograničenjima koja postotak dostupnosti krije. Ipak, primjenjuje se i nastavlja se naširoko koristiti. Stoga je važno razumjeti da morate odrediti vremensko razdoblje tijekom kojeg se izvode izračuni i dostavljaju izvješća, jer to može biti kritično za brojeve koji će biti u vašim izvješćima.
Na primjer, razmislite o IT tvrtki koja je pristala na uslugu 24x7 i 99% dostupnost. Pretpostavimo da postoji pauza od osam sati:
- ako izvješćujemo o dostupnosti na tjednoj bazi, tada je AST (Dogovoreno vrijeme usluge) 24 x 7 sati = 168 sati
- mjesečno AST (24 x 365) / 12 = 730 sati
- kvartalno AST (24 x 365) / 4 = 2190 sati
Stavljanje ovih brojeva u jednadžbu dostupnosti daje:
- Tjedna dostupnost = 100% x (168-8) / 168 = 95,2%.
- Mjesečna dostupnost = 100% x (730 - 8) / 730 = 98,9%
- Kvartalna dostupnost = 100% x (2190-8) / 2190 = 99,6%
Svaki od njih je valjan pokazatelj dostupnosti usluge, ali samo jedan od njih ukazuje da je cilj ispunjen.
U pritvoru
Gotovo svaka IT tvrtka s kojom sam radio mjeri i izvješćuje o dostupnosti svojih usluga. Zaista učinkoviti IT odjeli rade sa svojim klijentima kako bi optimizirali vlastita ulaganja i osigurali izvrsnu dostupnost. No, nažalost, mnoge se IT tvrtke usredotočuju na brojeve u SLA-u i ne uspijevaju zadovoljiti potrebe svojih klijenata, čak i ako na kraju prikazuju dosljedne brojke u svojim izvješćima.
Ovo je dugačak članak, u nastavku su ključne točke koje su u njemu pokrivene:
- Ne morate kupcu reći da ste isporučili 98% dostupnosti ako ne razumijete utjecaj 2% zastoja
- Razgovarajte sa svojim klijentima i pobrinite se da razumijete utjecaj bilo kakvog zastoja na njih i krajnje kupce
- Razmislite o načinima zaštite kritičnih poslovnih procesa vaših klijenata
- Pronađite načine za mjerenje učestalosti i trajanja zastoja, kao i utjecaj zastoja na izvedbu, koji zadovoljavaju potrebe vaših klijenata
- Dogovorite se, dokumentirajte i odredite metriku dostupnosti na način koji ima smisla za vaše klijente i pomozite u planiranju
- Koristite odgovarajuće alate za ispravnu procjenu dostupnosti i izvješće o tome.
Što biste još htjeli dodati mom savjetu? Molimo napišite u komentarima.

Ugovor o razini usluge – dokument koji opisuje razinu usluge koju kupac očekuje od dobavljača, na temelju metrike primjenjive na tu uslugu, i utvrđuje odgovornost dobavljača ako se dogovorena metrika ne postigne.
Grubo rečeno, ako vam je internet isključen kod kuće, onda u Eventualno pljunut ćeš i otići u šetnju, u kino ili konobu, u najboljem slučaju nadajući se preračunavanju.
Ako vam se prekine veza u uredu, tada vam prestaje prodaja (kupci ne mogu dobiti i bez čekanja odgovora poštom odlaze drugim dobavljačima), računovodstvo ne može vršiti plaćanja (eto već iznevjeravate svoje partnere), a ako ste, recimo, trgovački ured, tada iznos gubitaka može doseći tisuće dolara (nećete moći kupiti ili prodati dionice na vrijeme).
Možda postoji lirska digresija o rezerviranju kanala itd., ali imamo primjer pred očima - zgradu kompleksa Moskva City, u kojoj se prije nekoliko godina pokazalo da su i glavni i rezervni kanal iz isti pružatelj usluga. A nevolja, kao što znate, ne dolazi sama. Kao rezultat toga, dva puta po 7-8 sati (u radno vrijeme) našli su se izvan kontakta s kompanijama s liste Fortune 500.
Stoga posebno pedantne pravne službe tvrtki čije je poslovanje posebno osjetljivo na kvalitetu komunikacije, nastoje izračunati visinu štete za tvrtku ne samo po trošku neiskorištenih usluga, već i po dobiti koju je klijent izgubio zbog komunikacije zastoja.
polazišta
Evo nekih pokazatelja koji se u ovom ili onom obliku nalaze u dokumentima operatera:
ASR (omjer napadaja odgovora)- parametar koji određuje kvalitetu telefonske veze u određenom smjeru. ASR se izračunava kao postotak broja telefonskih veza uspostavljenih kao rezultat poziva prema ukupno poziva upućenih u određenom smjeru.
PDD (odgoda nakon biranja)- parametar koji definira vremenski period (u sekundama) koji je protekao od trenutka poziva do trenutka uspostavljanja telefonske veze.
Omjer dostupnosti usluge- omjer vremena prekida pružanja usluge i ukupnog vremena kada bi usluga trebala biti pružena.
Omjer gubitaka paketa- omjer ispravno primljenih paketa podataka prema ukupnom broju paketa koji su poslani mrežom u određenom vremenskom razdoblju.
Vremenska kašnjenja u prijenosu paketa informacija- vrijeme potrebno za prijenos paketa informacija između dva mrežna uređaja.
Pouzdanost prijenosa informacija- omjer broja pogrešno odaslanih paketa podataka prema ukupnom broju odaslanih paketa podataka.
Razdoblja rada, vrijeme obavijesti pretplatnika i vrijeme obnove usluga.
Drugim riječima, dostupnost usluge od 99,99% znači da operater jamči ne više od 4,3 minute prekida komunikacije mjesečno, 99,9% - da usluga ne može biti pružena 43,2 minute, a 99% - da prekid može trajati više od 7 sati. U nekim praksama dostupnost mreže je ograničena i pretpostavlja se manja vrijednost parametra - in neradno vrijeme. Na različiti tipovi pružaju se i usluge (prometne klase). različita značenja indikatori. Na primjer, za glas je najvažniji indikator kašnjenja - trebao bi biti minimalan. I potrebna mu je mala brzina, plus neki se paketi mogu izgubiti bez gubitka kvalitete (do oko 1% ovisno o kodeku). Za prijenos podataka brzina je na prvom mjestu, a gubitak paketa trebao bi težiti nuli.
Svjetski standardi
U zapadnoj praksi uobičajeno je dati službeno izvješće o parametrima mreže za Prošle godine. Evo, na primjer, pokazatelja za internetski kanal za svibanj nekoliko ozloglašenih brendova.
Kašnjenje prijenosa signala (Latencija, ms)
| Sprintnet | Verizon | Kabelska i bežična | NTT | |||||
| Činjenica | Standard | Činjenica | Standard | Činjenica | Standard | Činjenica | Standard | |
| Europa | 18.9 | 45 | 15.178 | 30 | 17.6 | 35.0 | 24.00 | 35 |
| SAD | 36.91 | 55 | 42.851 | 45 | 45.9 | 65.0 | 45.83 | 60 |
| Azija | 83.78 | 105 | 100.640 | 125 | 48.3 | 90.0 | 47.34 | 95 |
| Europa Azija | 207.63 | 270 | - | - | 174.1 | 310.0 | 260.23 | 300 |
| Europa-SAD | 74.53 | 95 | 78.784 | 90 | 78.7 | 90.0 | 71.57 | 90 |
| Sprintnet | Verizon | Kabelska i bežična | NTT | |||||
| Činjenica | Standard | Činjenica | Standard | Činjenica | Standard | Činjenica | Standard | |
| Europa | 0 | 0.3% | 0.025% | 0.5% | 0 | 0.2% | 0 | 0.3% |
| SAD | 0.01% | 0.3% | 0.019% | 0.5% | 0.1% | 0.2% | 0 | 0.3% |
| Azija | 0 | 0.3% | 0.004% | 1% | 0 | 0.2% | 0 | 0.3% |
| Europa Azija | 0 | 0.3% | - | - | 0 | 0.2% | 0 | 0.3% |
| Europa-SAD | 0 | 0.3% | 0 | 0.5% | 0.1% | 0.2% | 0 | 0.3% |
| Sprintnet | Verizon | Kabelska i bežična | NTT | |||||
| Činjenica | Standard | Činjenica | Standard | Činjenica | Standard | Činjenica | Standard | |
| Europa | 0.0017 | 2 | 0.026 | 1 | - | - | 0 | 0.5 |
| SAD | 0.0007 | 2 | 0.058 | 1 | - | - | 0 | 0.5 |
| Azija | 0.0201 | 2 | - | - | - | - | 0 | 0.5 |
| Europa Azija | 0.0001 | 2 | - | - | - | - | 0 | 0.5 |
| Europa-SAD | 0.0001 | 2 | - | - | - | - | 0 | 0.5 |
Sprint ima stroži pristup prema sebi, a ako SLA nije ispunjen (barem u odnosu na), tada se korisniku vraća pretplata za cijeli mjesec u kojem je zabilježen problem.
U slučaju nedostupnosti usluge krivnjom NTT-a, operater si postavlja okvir za prepoznavanje i rješavanje problema u roku od 15 minuta – nakon čega se klijentu vraća od 1/30 do 7/30 mjesečne uplate. Ako SLA ne odgovara stopi kašnjenja signala, klijent može računati na jednokratni povrat dnevne uplate.
Naše stvarnosti
NA ruski posao pretežno međunarodni brendovi s poštovanjem se odnose prema SLA. Istodobno, sama se sintagma udomaćila i među kupcima u glavnom gradu, pa čak i srednje tvrtke ponekad zanimaju ovaj dokument. Ovdje bih želio napomenuti da sporazum o razini usluge ne zamjenjuje niti poništava standardne klauzule o odgovornosti operatora u ugovoru o usluzi, kao ni norme utvrđene zakonom i podzakonskim aktima (na primjer, Savezni zakon " O komunikacijama", Naredba br. 92 "O odobrenju normi o električnim parametrima glavnih digitalnih kanala i staza glavnih i intrazonalnih primarnih mreža VSS Rusije itd.), koje svi mi sveto slijedimo.
U praksi Gars Telekoma, u slučaju bilo kakvih "zajebavanja", sporovi se rješavaju u okviru postupka obrade kvarova i vremena ponovnog uspostavljanja usluge. Nesreće koje su dovele do kvara usluge moraju se otkloniti od 4 do 72 sata (ovisno o uzroku). Ako su navedeni parametri prekoračeni, pretplatniku se nadoknađuje svaki dodatni sat zastoja, a kada operater dosegne granične vrijednosti, postotak naknade se povećava.
Od zanimljivih slučajeva možete se sjetiti trgovine glazbeni instrumenti, koji je nas (operaterku) okrivio za pad prodaje klavira (telefon neko vrijeme nije radio). Ovdje se opet može usporediti s naprednim zapadom orijentiranim na klijente, ali bolje je okrenuti se ruskoj divljini, gdje ne postoji samo SLA - općenito, koncept "vrijeme oporavka usluge" ne postoji. U najboljem slučaju, vrijeme odgovora je 48 sati. Za primjere ne morate ni ići daleko - 15 km od St. Petersburga - a lokalni operater odbija bilo kakvu odgovornost. Bilo bi ružno govoriti u ime svih regionalnih operatera, ali to je, nažalost, više pravilo nego iznimka.
Kakvi se zaključci mogu izvući iz ovih priča?
- Nakon svađe se ne maše šakom - ako postoje kritični parametri za poslovanje, morate razmisliti o kojim i razgovarati s operaterom u fazi usklađivanja dokumenata
- Indikator na kojem treba stalno raditi je vrijeme oporavka usluge i razina tehničke podrške. Jer kad ništa ne radi, gore je nego kad radi, ali je loše (u ovom slučaju klijent barem može brzo i bezbolno promijeniti operatera)
- Također se isplati pobrinuti se za rezervaciju unaprijed, a usluga mora biti od neovisnih operatera, od kojih barem jedan mora biti fiksni.
Definicije
Svi znaju da u Microsoft Exchangeu DAG znači "Grupa dostupnosti baze podataka" - "Grupa dostupnosti baze podataka".
Baza podataka — jer razinavisoka dostupnost poslužitelji Exchange 2010 poštanski sandučići, određuje baza podataka, a ne poslužitelj, odnosno baza podataka je li ta jedinica, koji se može kretati između više poslužitelja unutar grupe dostupnosti baze podataka u slučaju kvara. Ovaj princip je poznat poput prenosivosti baze podataka.
Skupina- jer je određen opseg raspoloživosti poslužitelji poštanskih sandučića u DAG, koji spojeno u failover klaster i raditi zajedno kao grupa.
DostupnostČini se da ovaj izraz najmanje očito a najviše zbunjujuće. Čudno, ovaj pojam ima izravan matematička definicija i igra važnu ulogu ulogu u razumijevanju načela dizajna Razmjena u cjelini.
Wikipedia definira"pristupačnost" kao oznaka jedno od sljedećeg:
Stupanj do kojeg je sustav, podsustav ili oprema u određenom radnom stanju, slučaju kvara, barem je nepoznat, tj. slučajno vrijeme. Jednostavno rečeno , pristupačnost je udio vremena kada sustav nalazi se u stanju funkcioniranje. Matematički to izraženo kao 1 minus nedostupnost.
Omjer(i) ukupnog vremena funkcioniranje unutar datog interval do (b) vrijednost intervala .
U terminima teorija vjerojatnosti, ova definicija znači isto: vjerojatnost da ovaj sustav ili komponenta "u radnom stanju" u bilo kojem proizvoljni trenutak vrijeme .
Matematički to može se mjeriti brojanjem vremena koliko je sustav dostupan ("Uptime") za neke velika statistika reprezentativno razdoblje(obično godina) i dijeljenjem s ukupnom duljinom razdoblja. Korištenje široko prihvaćenih izraza srednje vrijeme između kvarova (MTBF - srednje vrijeme između kvarova) i prosječno vrijeme usluge (MTTR - srednje vrijeme do popravka)— predstavljamo dostupnost sustava/vrijeme između kvarova, zastoj sustava tijekom bilo koje date kvar , — dostupnost može se izraziti kao frakcija:
Suprotan matematička karakteristika bit će vjerojatnost kvara:

Dostupnost često se izražava kao"broj devetki", prema sa sljedećom tablicom:
| Razina dostupnosti | Vrijednost dostupnosti | Vjerojatnost kvara | Dopušteni zastoji godišnje |
| Dvije devetke | 99% | 1% | 5256 minuta = 3,65 dana |
| Tri devetke | 99.9% | 0.1% | 525,6 minuta = 8,76 sati |
| Četiri devetke | 99.99% | 0.01% | 52.56 minuta |
| pet devetki | 99.999% | 0.001% | 5.26 minuta |
Naravno, vrijednost pristupačnosti bit će drugačije ovisno o uzimamo li u obzir planirani(planirani) i neplanirani (neplanirani) zastoji ili samo neplanirani zastoji. Ugovor o razini usluge (SLA), koji izražava poslovni zahtjevi dostupnost mora sadržavati specifične informacije. Ali u svim slučajevima prisutnost jednog ili drugog sustav ili komponenta ovisi o mnogim faktorima, i iznimno bitno definirati i razumjeti ove ovisnosti i kako utječu dostupnost .
Utjecaj ovisnosti na dostupnost
Dostupnost baze podataka Razmjena poštanskih sandučića ovisi o prisutnosti mnogih drugih usluge i komponente- na primjer , podsustav za pohranu,koji udomljuje bazu podataka, poslužitelj na kojem pokretanje ove baze podataka, Mrežna veza ovaj server itd. Svi ovi važne komponente, i neuspjeh bilo kojeg od njih će značiti neuspjeh usluge, čak i ako sama baza podataka je savršeno funkcionalan. To znači da kako bi baza podataka bila dostupna kao usluga, svaka ovisnost je također treba biti dostupan. Ako ćemo pravo identificirati i izolirati komponente ovisnosti, tada možemo matematički izračunati kako one određuju rezultirajuću razinu dostupnost baze podataka Exchange poštanski sandučić.
Za ovo baze podataka poštanskih sandučića, sljedeće komponente može se smatrati kao kritične ovisnosti:
diskovni podsustav baze podataka / sustav za pohranu - na primjer A1 ;
poslužitelj poštanskog sandučića(i hardver i i programske komponente) - A2 ;
S klijentski pristupni poslužitelj(hardver i softver komponente) - zapamtite da u Exchange 2010 sve klijenti se povezuju s baza poštanskih sandučića samo kroz Poslužitelj klijentskog pristupa (poslužitelj s ulogom klijentskog pristupa), i pretpostavimo od kojeg je CAS instaliran odvojeno poslužitelji poštanskih sandučića- A3;
Mrežna veza
između klijenata i Klijentski pristup poslužitelju i između poslužitelja klijentski pristup i poslužitelj poštanskog sandučića— A4;
struja u podatkovnom centru gdje se nalaze serveri i sustavi skladištenja— A5.
Ovaj popis mogao nastaviti… Na primjer, Active Directory i DNS također predstavljaju kritična ovisnost za Exchange. Osim toga, u dodatak čistom tehnološkog ovisnosti, dostupnost ima utjecajačimbenici kao što su ljudska pogreška, nepravilno obavljanje standardnih operacija održavanja, nedostatak koordinacije timovi za podršku. Sve ovo može dovesti do neoperabilnost. Nećemo pokušati sastaviti bilo koji iscrpan popis ovisnosti, i umjesto toga, usredotočimo se na kako utječu na cjelokupno dostupnost usluge.
Pošto same ove komponente neovisni jedni o drugima, prisutnost svakog od njih je neovisna događaj i rezultirajuća razina dostupnosti baze podataka Razmjena poštanskih sandučića je kombinacija svi ovi događaji (drugim riječima, do baza poštanskih sandučićabio dostupan za svi ti klijenti komponente bi trebale dostupno ). Iz teorija vjerojatnosti, vjerojatnost kombinacije nezavisni događaji je proizvod pojedinačne vjerojatnosti za svaki događaj:

Na primjer, ako bacite tri novčića, pad vjerojatnosti"orao" za sva tri novčića (1/2) * (1/2) * (1/2) = 1/8.
Važno je razumjeti da vrijednost pristupačnosti ne može biti više od 1(ili 100%), i kao rezultat dostupnost usluge proizvod je dostupnosti pojedinih komponenti čija vrijednost dostupnosti ne može biti više nego najniža komponenta ovisnosti o dostupnosti.
Ovo se može ilustrirati na prikazanom primjeru u sljedećoj tabeli(brojevi su približni):
| Kritična ovisnost | Vjerojatnost kvara | Razina dostupnosti |
| Poslužitelj poštanskih sandučića i pohrana | 5% | 95% |
| Poslužitelj klijentskog pristupa | 1% | 99% |
| Neto | 0.5% | 99.5% |
| Hrana | 0.1% | 99.9% |
| 6.51383% | 95% x 99% x 99,5% x 99,9% = 93,48617% |
Iz ovog primjera, možete vidjeti kako kritički važne ovisnosti utjecati na dostupnost usluge. Čak za baze podataka poštanskih sandučića koji nikad ne uspijeva ( ne bit će oštećeni, nikada neće dobiti nikakav virusne infekcije itd.), dostupnost i dalje ostaje ispod 93,5%!
zaključak: Veliki broj dostupnost ovisnosti o uslugama se smanjuje.
Sve što ćemo učiniti za smanjenje broja ili utjecaj ovisnosti imat će pozitivan učinak na općem dostupnost usluge. Na primjer , mogli bismo poboljšati situacija kroz pojednostavljenje i osigurati upravljanje poslužiteljem i optimizacija radni postupci. S tehničke strane, mi možemo probati smanjiti količinu ovisnosti o uslugama izradom našeg dizajna lakše, na primjer, eliminirajući složene sustave za pohranu temeljene na SAN-u, optičke sklopke, kontrolere polja, pa čak i RAID kontrolere i zamjenjujući ih jednostavnim DAS-om s minimalnim pokretni dijelovi.
Smanjenje ovisnosti o usluzi samo po sebi ne može biti dovoljno da donijeti pristupačnost na željenu razinu. Još jedan vrlo učinkovita metoda
povećati dostupnost i minimizirati utjecaj kritične ovisnosti o održavanju je privući razne metode rezervacije kao što su korištenje dva izvora napajanja, NIC Timing , veza poslužitelja na nekoliko mrežne sklopke koristeći RAID za operacijski sustav, postavljanje hardverskih balansera za poslužitelje pristup klijentu i više kopija baze podataka poštanskih sandučića. Ali kako točno raste povećanje viška zaposlenih omogućuje postizanje visoke dostupnosti? Idemo detaljnije smatrati uravnoteženje opterećenja i više kopija baze podataka kao važno primjeri .
Kako rezervacije utječu na dostupnost
Konceptualno, sve metode redundantnosti znače isto: postoji više od jedne kopije komponenta koja je dostupna i može se koristiti ili u isto vrijeme (kao kod balanseri opterećenja) ili kao zamjena(kao što je slučaj sa više kopija baze podataka). Pretpostavimo imamo n kopije ovoga komponenta (n poslužitelja u CAS nizu ili n kopije baze podataka u DAG-u). Čak i ako jedan od njih izlazi iz reda, drugi još uvijek može se koristiti za osigurati visoka razina pristupačnost. Jedina situacija kada naiđemo na stvarni kvar usluge, kada sve instance više nisu dostupne.
Kao što je prethodno definirano, vjerojatnost kvara za bilo koga ovaj primjer P \u003d 1 - A. Svi primjeri statistički neovisno jedno od drugog, što znači da izvođenje ili neuspjeh nijedan od njih ne utječe na dostupnost u drugim slučajevima. Na primjer, neuspjeh ovoga kopije baze podataka ne utječe vjerojatnost kvara za drugi primjerak ovu bazu podataka(logična nijansa je moguća, kada će oštećena kopija prenijeti promjene na druge instance, ali hajde ignoriraj ovo faktor - na kraju, uvijek možete koristiti odgođenu kopiju baze podataka ili opciju oporavka pomoću tradicionalna sigurnosna kopija).
Opet koristeći isti teorem teorija vjerojatnosti, vjerojatnost kvara skup od n neovisnih komponenti je proizvod vjerojatnosti za svaku komponentu. Budući da su sve komponente ovdje identične (različite instance istog objekta):

Očito je kako P< 1, P n manje P, što znači da vjerojatnost kvara smanjuje, a sukladno tome, povećava se dostupnost:

Razmotrite neke pravi primjer iz života radi jasnoće. Recimo što instaliramo više kopija baze podataka poštanskih sandučića; svaka kopija nalazi se na jednom SATA disku. Prema statistikama, stopa kvarova SATA diskova je ~ 5% tijekom godine, što nam daje 5% vjerojatnost kvara: P = 0,05 (što znači 95% : A = 0,95). Kako će se promijeniti pristupačnost? kako dodajete kopije baze podataka? Pogledajmo sljedeća tablica:
| Broj kopija | Vjerojatnost kvara | Razina dostupnosti |
| 1 | P 1 \u003d P \u003d 5% | A 1 = 1 - P 1 = 95% |
| 2 | P 2 \u003d P 2 \u003d 0,25% | A 2 = 1 - P 2 = 99,75% |
| 3 | P 3 \u003d P 3 \u003d 0,0125% | A 3 = 1 - P 3 = 99,9875% |
| 4 | P4 = P4 = 0,000625% | A 4 = 1 - P 4 = 99,9994% |
Impresivan? Uglavnom, svaki dodatna instanca ulazi baza podataka na SATA disku faktor množenja 5% ili 1/20, pa vjerojatnost stopa neuspjeha postaje 20 puta manja sa svakom kopijom (i sukladno tome, dostupnost se povećava). Čak i to možemo vidjeti najnepouzdaniji SATA diskovi, predstavljamo samo 4 kopije baze podataka donosi nam dostupnost baze podataka u pet devetki.
to već jako dobro, ali možemo li učiniti još bolje? Možemo li povećati dostupnost ipak bez činjenja arhitektonske promjene(na primjer, prilikom dodavanja drugog kopije baze podataka)?
Zapravo, možemo. Ako poboljšamo individualnu pristupačnost bilo koja komponenta ovisnost, hoće pojačivač opća dostupnost usluga, i dovest će do mnogo toga jači učinak od od dodavanja suvišna komponenta. Na primjer, jedan od mogućih načina da to učinite, je korištenje Nearline SAS pogoni umjesto SATA pogona. Nearline SAS diskovi imaju godišnju stopu kvarova od ~2,75% umjesto ~5% za SATA. Ovo će smanjiti vjerojatnost kvara za komponentu za pohranu i time povećati ukupni dostupnost usluge. Dovoljno je usporediti učinak od dodavanje višestrukih kopije baze podataka:
5% AFR omjer = 1/20 = množenje svake nove instance čini štetu baze podataka su 20 puta rjeđe.
2,75% AFR = 1/36 faktor množenja= svaka nova instanca čini štetu baze podataka su 36 puta rjeđe.
to značajan utjecaj nadostupnost baze podataka također objašnjava upute za korištenje koncepta Exchange Native Data Protection, koji objašnjava da se više kopija baze podataka može zamjena za tradicionalne sigurnosne kopije ako su raspoređene dovoljno(tri ili više).
Ista logika vrijedi do raspoređivanje nekoliko klijentski pristupni poslužitelji u nizu CAS, nekoliko mrežne sklopke itd. Pretpostavimo da mi postavio 4 kopije baze podataka i 4 klijentski pristupni poslužitelj, i vratimo se na komponentu tablice dostupnosti koju smo ranije analizirali:
| Kritična ovisnost | Vjerojatnost kvara | Razina dostupnosti |
| Poslužitelj poštanskog sandučića i pohrana (4 kopije) | 5% ^ 4 = 0.000625% | 99.999375% |
| Poslužitelj klijentskog pristupa (4 poslužitelja postavljena zasebno) | 1% ^ 4 = 0.000001% | 99.999999% |
| Neto | 0.5% | 99.5% |
| Hrana | 0.1% | 99.9% |
| Ukupna vrijednost (ovisi o svim navedenim komponentama) | 0.6% | 99.399878% |
Mi možete vidjeti kako upravo smo rasporedili 4 klijentski pristup poslužitelju i 4 kopije baze podataka, vjerojatnost kvara iz općih usluga smanjen za više od 10 puta (sa 6,5% na 0,6%) i sukladno tome, dostupnost usluge porastao s 93,5% na puno respektabilnijih 99,4%!
Zaključak: Dodavanje redundancije za ovisnosti povećava dostupnost.
Povežimo se zajedno
Zanimljivo pitanje iz prethodnih nalaza. Mi analizirani dvije različite faktor utjecaja za generala dostupnost usluge dva različiti putevi
i došao do dva jasna zaključka:
dodajući sustavniji ovisnosti smanjuju dostupnost
dodavanje redundancije u ovisnostima sustava povećava dostupnost
Što se događa ako kombinirati oba faktora u rješenje? Koje su tendencije jače?
Razmotrite sljedeći scenarij:
Koristimo dva poslužitelja poštanskih sandučića u DAG-u s dvije kopije baze podataka poštanskih sandučića(jedan primjerak na svakom poslužitelju) i koristimo dva poslužitelja klijentski pristup u nizu s uravnoteženjem opterećenja. (Radi jednostavnosti, hoćemo uzeti u obzir samo Dostupnost baze podataka poštanskih sandučića za klijentske veze bez razmatranja uloge Hub Transport Server i UM)
. Ako to pretpostavimo svaki poslužitelj ima svoje pojedinac vjerojatnost kvara P, bi li takav sustav bio bolji ili lošiji od jednog instaliranog samostalnog Exchange poslužitelja s obje uloge poslužitelja poštanskog sandučića i klijentski pristup?

U prvom scenariju, poslužitelji poštanskih sandučića neovisni su i postat će nedostupan samo ako oba poslužitelja zakažu. Vjerojatnost neuspjeha set od dva poslužitelji poštanskih sandučića bit će P× P = P 2. Sukladno tome, njegova dostupnost će biti AMBX = 1 – P2. Slijedeći istu logiku, usluga CAS bit će nedostupan samo ako oba poslužitelja klijentski pristup neće uspjeti, pa vjerojatnost neuspjeh za set od dva klijentski pristupni poslužitelji bit će opet P× P = P 2
i sukladno tome, njegova će dostupnost CAS = 1 – P2.
U ovom slučaju, kao što smo već shvatili, dva poslužitelja poštanskih sandučića ili dva poslužitelja klijentski pristup su primjeri blagoglagoljiv komponente sustava.
Nastavimo ovaj scenarij. Kako bi cijeli sustav bio dostupan, oba skupa poslužitelja (skup poslužitelja poštanskih sandučića i skup klijentski pristupni poslužitelji) treba biti dostupan istovremeno . Ne ne uspjeti u isto vrijeme ali u isto vrijeme dostupan jer sada predstavljaju sistemski ovisnosti, ali ne suvišne komponente. To znači, da općenito dostupnost usluge je proizvodpristupačnostsvaki skup:
Naravno, druga opcija puno lakše, jer postoji samo jedan server i smatrati njegovu dostupnostjednostavno A = 1 – P.
Pa sada mi izračunate vrijednosti pristupačnost za oba scenarija. Z čije značenje iznad, (1-P 2
) 2
ili 1-P?
Ako se gradi karte obje funkcije, Vidjet ćemo sljedeće ponašanje:

Vidimo da za malu vrijednost P, prisutnost integrirani sustav od 4 poslužitelja je veći nego od jednog poslužitelja. Nema ništa iznenađujuće, ovo smo očekivali, zar ne? Međutim, na P ~ 0,618 sijeku se dva odjeljka, a na velike vrijednosti P jedan sustav poslužitelj zapravo ima veću dostupnost. Naravno, bilo bi vjerojatnije očekivati da bi vrijednost P trebala biti vrlo blizu nule stvaran život. Međutim, ako planiramo izgraditi vlastito rješenje s vrlo nepouzdanim komponentama, rješenje s jednim poslužiteljem vjerojatno je bolje.
Utjecaj točaka kvara
Nažalost, gore opisani scenariji implementacije rijetki su u stvarnom životu. Na primjer, kakav bi bio utjecaj promjene dostupnosti ako se postavi poslužitelj s više uloga? Primijetili smo da u gornjem primjeru kombinacija uloga poslužitelja učinkovito smanjuje broj ovisnosti o usluzi, pa je vjerojatno u redu? Što se događa ako smjestimo dvije kopije baze podataka iz iste baze podataka na istom SAN ili DAS polju? Što ako su svi poslužitelji spremnika spojeni na isti mrežni preklopnik? Što ako imamo sve gore navedeno i više od toga?
Sve te situacije suočavaju nas s konceptom točke neuspjeha. U gornjim primjerima hardvera poslužitelja, ili SAN polje ili mrežni prekidač predstavljaju točke kvara. Točka kvara prekida neovisnost ili redundantnost komponenti koje kombinira - na primjer, kvar hardverskih komponenti poslužitelja u poslužitelju s kombinacijom uloga znači da sve uloge na tom poslužitelju postaju nedostupne; sukladno tome, kvar diska ili SAN polja znači da sve kopije baza podataka koje se nalaze na tom disku ili polju postaju nedostupne.
Ali imati točku neuspjeha nije nužno loša stvar. Važna razlika je u tome što se komponente koje čine točku kvara razlikuju od ovisnosti sustava ili redundantnih komponenti sustava. Pogledajmo dva gornja primjera da bismo razumjeli ovu razliku.
Poslužiteljska skripta s više uloga
Usporedimo prisutnost dvaju različitih sustava:
1. Uloge poslužitelja poštanskog sandučića i poslužitelja klijentskog pristupa smještene na istom poslužitelju koji ima vjerojatnost kvara hardvera P;
2. Iste uloge nalaze se na dva odvojena poslužitelja, svaki s istom vjerojatnošću kvara hardvera.
U prvom slučaju hardver jednog poslužitelja predstavlja točku kvara. To znači da su sve hostirane uloge dostupne ili nisu dostupne. Jednostavno je, općenito, dostupnost takvog sustava je A = 1 - P.
U drugom slučaju, općenito, usluga će biti dostupna samo kada su oba poslužitelja dostupna neovisno (jer je svaka uloga kritična ovisnost). Prema tome, na temelju teorije vjerojatnosti, njegova će prisutnost biti A × A = A2.
Opet, kao a<1, это означает, что A2 < А, так во втором случае доступность будет ниже.
Čini se da možemo dodati druge uloge Exchange poslužitelja (Hub Transport i Unified Messaging ako je potrebno) na isti način bez prekida ove logike.
Zaključak: Hosting uloga poslužitelja Exchange na poslužitelju s više uloga poboljšava ukupnu dostupnost usluge.
Scenarij dijeljene pohrane
Sada pogledajmo drugi scenarij neuspjeha (dvije kopije Exchange baze podataka na istom polju) i usporedimo dostupnost baze podataka u sljedeća dva slučaja:
1. Dvije kopije baza podataka koje se nalaze na istoj pohrani (SAN ili DAS polje), koja ima vjerojatnost kvara P;
2. Iste kopije baza podataka smještene na dva odvojena sustava za pohranu podataka, svaki s istom vjerojatnošću kvara.
U prvom slučaju dijeljena pohrana predstavlja točku kvara. Kao i u prethodnom scenariju, to znači da su obje kopije baze podataka dostupne ili nisu dostupne u isto vrijeme, tako da je ukupna razina dostupnosti ponovno A = 1 - P.
U drugom slučaju, općenito će usluga biti dostupna ako je barem jedan sustav dostupan, a nedostupna samo ako oba sustava zakažu. Sustavi skladištenja su neovisni. Stoga je vjerojatnost kvara za cjelokupnu uslugu P × P = P2 i, sukladno tome, ukupna dostupnost usluge je A = 1 – P2.
Opet, ako je P< 1, то это означает, что Р2 <Р, и, следовательно, 1 – P2 >1 - P. To znači da je razina dostupnosti u drugom slučaju puno viša.
Zaključak: Postavljanje kopija iste baze podataka na isti sustav za pohranu smanjuje ukupnu dostupnost usluge.
Dakle, koja je razlika između ova dva scenarija, zašto uvođenje točaka kvara povećava dostupnost u prvom slučaju, a smanjuje dostupnost u drugom?
To je zato što točka kvara u prvom slučaju kombinira održavanje ovisnosti, učinkovito smanjujući njihov broj i stoga povećavajući dostupnost, dok točka kvara u drugom slučaju kombinira redundantne komponente, učinkovito smanjujući redundanciju i stoga je dostupnost degradirana.
Svi ovi koncepti i zaključci mogu se prikazati u sljedećem obliku:

zaključke
Arhitektura Exchangea 2010 pruža snažan mogućnostima za dodavanje zalihost (na primjer, raspoređivanje nekoliko kopije baze podataka ili više poslužitelja za klijentski pristup u nizu CAS) i smanjiti broj sustavnih ovisnosti ( kombiniranjem Uloge Exchange poslužitelja ili pomoću jednostavan arhitekture pohrane bez pretjerana količina kritične komponente). Jednostavna pravila i formule predstavljen u ovaj članak dopustiti izračunati utjecaj na troškove pristupačnost od raspoređivanja dodatni kopije baze podataka ili iz kombinacije Uloge Exchange poslužitelja. T također moguće izračunati utjecaj točke kvara. Stvaran život rijetko uklapa u jednostavan osnovni scenariji, i trebatimnogo složenije kalkulacije, Dobiti razuman procjene pristupačnost stvarni sustavi; može se olakšati ilako se mjeri razina dostupnosti statistički i potvrditi, zadovoljava li zahtjeve SLA. svejedno, razumijevanje faktora koji utječu na pristupačnost zajedno S složenost tehničko rješenje trebao pomoći oblikovati riješenje desno i dohvatiti značajno povećanje Općenito pristupačnost usluge čak za najzahtjevnije poslovne zahtjeve.
Gore opisana metrika može se koristiti pri sklapanju ugovora o dostupnosti usluge s korisnicima. Ovi su ugovori dio Ugovora o razini usluge. Sljedeća formula pomaže odrediti ispunjava li postignuta razina dostupnosti dogovorene zahtjeve:
Riža. 14.6. Formula dostupnosti (izvor: OGC)
Ostvareno vrijeme rada sustava jednako je razlici između dogovorenog vremena rada i zastoja koji je nastao. Na primjer: ako je postignut dogovor o 98% dostupnosti usluge radnim danom od 7.00 do 19.00 sati iu tom razdoblju je došlo do dvosatnog prekida rada usluge, tada će postignuti uptime (postotak dostupnosti) biti jednak:
(5x12-2)/(5 x 12) x 100% = 96,7%
Analiza zastoja sustava (SOA)
Ovom se metodom mogu utvrditi uzroci kvarova, proučavati učinkovitost IT organizacije i njezinih procesa te predstaviti i implementirati prijedloge za poboljšanje usluge.
Karakteristike SOA metode:
Širok opseg: nije ograničen na infrastrukturu i također pokriva procese, postupke i aspekte korporativne kulture;
Razmatranje problema sa stajališta kupca;
Zajednička implementacija metode od strane predstavnika naručitelja i IT organizacije (SOA metod tim).
Prednosti ove metode su učinkovitost pristupa, izravna komunikacija kupca i dobavljača te širi prostor za prijedloge za poboljšanje usluge.
Radno mjesto tehničkog nadzora (TOR)
Ova se metoda sastoji od promatranja jednog odabranog aspekta dostupnosti od strane posvećenog IT tima. Može se koristiti u slučajevima kada konvencionalna sredstva ne pružaju dovoljnu podršku. TOP metoda omogućuje kombiniranje znanja dizajnera i voditelja sustava.
Izračuni dostupnosti usluge
Glavna prednost ove metode je racionalan, učinkovit i neformalan pristup koji brzo daje rezultate.
itil softver za automatizaciju procesa
- bmc softver
- računalni suradnici
- Hewlett Packard
- Microsoft
bmc softver
BMC Software je svjetski poznati razvojni programer i pružatelj alata za upravljanje mrežom, aplikacijama, bazama podataka, ERP i CRM koji poboljšavaju dostupnost, izvedbu i mogućnost oporavka kritičnih poslovnih aplikacija i podataka. BMC proizvodi dostupni su za širok raspon platformi, uključujući razne implementacije i verzije UNIX-a, Windows-a, OS/2, OS/390, OpenVMS-a i NetWare-a. Od značajki karakterističnih za BMC proizvode, prije svega treba istaknuti da su oni usmjereni na podršku korisničkim ugovorima o razini usluge (Service Level Agreement, SLA) i izgradnju funkcionalnog modela usmjerenog na implementaciju takvog sporazuma, kao i njihovu visoku performanse (slika 1). Tvrtka nudi sljedeće obitelji proizvoda za upravljanje IT infrastrukturom:
- Upravljanje BMC aplikacijama- alat je dizajniran za upravljanje performansama i dostupnošću poslovnih aplikacija (uključujući aplikacije iz Oracle i SAP) i poslužiteljskih proizvoda (kao što su Microsoft Exchange i J2EE poslužitelji BEA WebLogic, IBM WebSphere itd.);
- BMC upravljanje bazom podataka- alat za administraciju, upravljanje performansama i oporavak baza podataka kojima upravljaju vodeći proizvođači DBMS-a - Oracle, IBM, Microsoft, Sybase;
- BMC upravljanje infrastrukturom- alat za upravljanje poslužiteljskim i glavnim operativnim sustavima, pohranom podataka, mrežama, hardverom, međuprogramom i za optimizaciju performansi ovih kategorija softvera;
- BMC Operations Management- alat za obavljanje rutinskih operacija po rasporedu i za izvještavanje o događajima u mreži;
- BMC Remedy Service Management- alat za traženje, otkrivanje, modeliranje kvarova u aplikacijama i reagiranje na njih;
- BMC sigurnosno upravljanje- alat za upravljanje korisničkim pravima pristupa aplikacijama i korporativnim resursima.
Podaci BMC aplikacije mogu se pohraniti u konfiguracijsku bazu podataka BMC Atrium CMDB (Configuration Management Database), koja ima prikladne alate za vizualizaciju podataka.
bmc softver
Imajte na umu da BMC proizvodi uključuju dokumentirano sučelje za programiranje aplikacija koje vam omogućuje stvaranje vlastitih rješenja na temelju njih i integraciju BMC alata s drugim aplikacijama.

Riža. 1. Područja upravljanja IT infrastrukturom pokrivena BMC proizvodima
računalni suradnici
Computer Associates (CA) Unicenter obitelj proizvoda za upravljanje IT infrastrukturom može se prilagoditi tako da odgovara gotovo svakom računalnom okruženju.
Ova obitelj uključuje sljedeće proizvode:
- Unicenter upravljanje imovinom- alat za automatizaciju upravljanja IT imovinom poduzeća, uz pomoć kojeg se provodi sveobuhvatno računovodstvo i kontrola IT resursa. Funkcionalnost sustava Unicenter Asset Management pomaže u poboljšanju kvalitete upravljačkih odluka povezanih s IT imovinom poduzeća i smanjenju povezanih rizika. Unicenter Asset Management prati korištenje aplikacija na poslužiteljima, računalima i drugim klijentskim uređajima. Osim toga, ovaj proizvod vam omogućuje automatizaciju procesa upravljanja IT imovinom, uključujući računovodstvo i inventar softvera i hardvera koji rade u mreži poduzeća, održavanje različitih komponenti IT infrastrukture, administraciju licenci i izvješćivanje u heterogenim okruženjima (Sl. 2);

Riža. 2. Područja integriranog upravljanja IT infrastrukturom pokrivena proizvodima Computer Associates
- Unicenter Software Delivery- pruža automatizaciju procesa implementacije i ažuriranja softvera na stolnim, mobilnim i ručnim računalima, kao i na poslužiteljima u heterogenim mrežnim okruženjima, uključujući isporuku aplikacija, distribuciju zakrpa i ažuriranja, upravljanje konfiguracijom sustava i vraćanje instalacija na različite softverske i hardverske platforme . Ovaj proizvod stvara uvjete za povećanje učinkovitosti IT usluga i smanjenje troškova informacijske podrške poslovanju automatizacijom IT procesa i implementacijom aplikativnih kataloga s naprednim samouslužnim mogućnostima. Jedna od ključnih prednosti Unicenter Software Delivery je visok stupanj automatizacije procesa instalacije i održavanja softvera te fleksibilna i granularna kontrola dozvola za isporuku aplikacija;
- Unicenter daljinski upravljač je pouzdan i siguran korporativni sustav za daljinsko upravljanje Windows računalima. Popis zadataka daljinskog upravljanja uključuje održavanje udaljenih usluga kao što su mrežne aplikacije, administracija poslužitelja i daljinsko upravljanje računalima krajnjih korisnika (na primjer, prilikom pružanja tehničke podrške). Ovaj sustav jedno je od najboljih industrijskih rješenja u svojoj klasi i pruža centralizirano održavanje sustava, upravljanje temeljeno na pravilima, kontrolu pristupa, reviziju sesija i napredne administrativne mogućnosti. Unicenter Remote Control u potpunosti ispunjava zahtjeve velikih poduzeća u pogledu daljinskog upravljanja i omogućuje operateru istovremeno obavljanje nekoliko zadataka odjednom: kopiranje datoteka na udaljeno računalo, komunikaciju s korisnikom, pokretanje aplikacija, praćenje i snimanje korisničkih radnji te upravljanje konfiguracijske i sigurnosne postavke. Treba napomenuti da se prilikom razvoja Unicenter Remote Control posebna pozornost posvetila skraćenju vremena implementacije i razvoja sustava.
Hewlett Packard
HP OpenView je paket softverskih proizvoda usmjerenih na upravljanje informacijskom tehnologijom poduzeća bilo koje veličine - od malih poslužiteljskih sustava temeljenih na sustavu Windows do velikih distribuiranih sustava temeljenih na različitim verzijama UNIX-a, Linuxa i Windowsa, koji sadrže nekoliko tisuća računala. Ovaj kompleks uključuje alate za upravljanje mrežama, operativnim sustavima, aplikacijama, kao i njihovim performansama, kopiranje i pohranjivanje podataka, usluge.
HP OpenView portfelj softverskih rješenja sastoji se od nekoliko obitelji proizvoda (Slika 3), uključujući upravljanje poslužiteljima i aplikacijama, pohranu, umrežavanje, internetske tehnologije i telekomunikacijsku opremu (postoji niz HP OpenView proizvoda dizajniranih posebno za telekomunikacijske tvrtke, a danas HP je najpoznatiji dobavljač kontrola telekomunikacijske opreme). Zasebno bilježimo prisutnost alata za upravljanje IT uslugama u portfelju HP rješenja.

Riža. 3. Portfelj softverskih rješenja HP OpenView za IT odjele
Alatima za upravljanje poslužiteljima i aplikacijama prvenstveno treba pripisati HP OpenView Operations za Windows i HP OpenView operacije za Unix. Ovi su proizvodi dizajnirani za praćenje i upravljanje performansama aplikacija i kontrolu mrežnih i aplikacijskih događaja. HP OpenView Operations za Windows integrira se s alatima za upravljanje mrežnom infrastrukturom HP OpenView Network Node Manager, koji vam omogućuje da automatski tražite nove poslužitelje dodane mreži, a zatim automatski postavite potrebne komponente i pravila na temelju rezultata pretraživanja usluge.
Hewlett Packard
Za upravljanje performansama aplikacije ova obitelj uključuje alate HP OpenView Performance Manager i Agenti za izvedbu, koji omogućuju korištenje jedinstvenog sučelja za centralno praćenje, analizu i predviđanje korištenja resursa u distribuiranim i heterogenim okruženjima, kao i HP Open View Performance Insight, koji pomaže pratiti događaje u mreži i aplikacijama, analizirati ih. Rješenja Paketi izvješća HP OpenVew i HP Open View Reporter dizajniran za izradu izvješća o radu distribuirane IT infrastrukture poduzeća na temelju podataka primljenih iz HP OpenView aplikacija.
Za upravljanje identitetom i pristupom IT resursima, obitelj HP OpenView uključuje proizvode HP OpenView Select Identity, HP OpenView Select Access i HP OpenView Select Federation, te za upravljanje sigurnosnom kopijom i vraćanjem podataka poslužiteljskog DBMS-a - HP OpenView Storage Data Protector. Posljednji od ovih proizvoda je rješenje za zaštitu podataka i oporavak od katastrofe na razini poduzeća koje implementira tehnologiju trenutnog oporavka, kao i alternative oporavka od katastrofe za uklanjanje neplaniranih zastoja, što vam omogućuje vraćanje ispravnosti informacijskog sustava u nekoliko minuta.
Također primjećujemo prisutnost u ovoj obitelji proizvoda dizajniranih za interakciju s krajnjim korisnicima kako bi se poboljšala kvaliteta njihove usluge, - HP OpenView Service Desk, kao i alate za praćenje poslovnih procesa HP OpenView Business Process Insight i alati za upravljanje servisno orijentiranom arhitekturom - HP OpenView Service Oriented Architecture Manager.
Hewlett Packard
Ova obitelj proizvoda pruža rješenje za upravljanje internetskim uslugama Internetske usluge HP OpenView, koji omogućuje vanjsko ispitivanje aplikacijskih usluga, internetskih usluga i protokola modeliranjem korisničkih zahtjeva prema imenicima, uslugama e-pošte, web uslugama, uslugama daljinskog pristupa (uključujući dial-up i bežični pristup).
IBM Tivoli obitelj proizvoda, dizajnirana za upravljanje aplikacijama u poduzećima različitih veličina, temelji se na skupu osnovnih komponenti od kojih se gradi rješenje specifično za poduzeće. Glavna karakteristika ove obitelji proizvoda je tzv. proaktivno upravljanje IT infrastrukturom, koje je u stanju detektirati i otkloniti kvarove i prije nego što se pojave. Proizvodi obitelji Tivoli dostupni su za platforme AIX, HP-UX, Sun Solaris, Windows, Novell NetWare, OS/2, AS/400, Linux, z/OS, OS/390. Imajte na umu da nedavno IBM preporučuje implementaciju Tivoli obiteljskih proizvoda kako bi se slijedile metode ITIL (Information Technology Infrastructure Library) knjižnice, pomičući fokus u pozicioniranju svojih proizvoda s upravljanja IT resursima i sustavima na upravljanje IT uslugama (Slika 4).

Riža. 4. Neki od Tivoli softverskih proizvoda koji podržavaju ITIL proces upravljanja uslugom
Obitelj proizvoda Tivoli uključuje rješenja za upravljanje konfiguracijom i operativnu podršku za:
- IBM Tivoli Configuration Manager- omogućuje upravljanje instalacijom i ažuriranjem softvera, uključujući i PDA uređaje;
- IBM Tivoli License Manager- dizajniran za inventar softvera;
- IBM Tivoli daljinski upravljač- omogućuje vam postavljanje pravila za upravljanje IT resursima poduzeća i daljinsko upravljanje stolnim sustavima;
- IBM Tivoli Workload Scheduler- omogućuje vam automatizaciju radnih opterećenja.
Uz alate za upravljanje konfiguracijom, Tivoli obitelj proizvoda uključuje rješenja za upravljanje performansama i dostupnošću:
- IBM Tivoli Monitoring- implementirati distribuirani nadzor različitih sustava, automatsku detekciju i otklanjanje problema te analizu trendova;
- IBM Tivoli Monitoring za baze podataka(Podržani su DBMS-ovi koje proizvode IBM, Oracle i Microsoft) i Tivoli Manager za Sybase- za centralizirano upravljanje poslužiteljima i bazama podataka;
- IBM Tivoli Monitoring za web infrastrukturu- upravljanje web-poslužiteljima i aplikacijskim poslužiteljima;
- IBM Tivoli Monitoring za aplikacije- upravljanje SAP poslovnim aplikacijama;
- IBM Tivoli Analyzer za Lotus Domino 6.0 i IBM Tivoli Monitoring za performanse transakcija- otkrivanje problema s performansama u sustavima koji se temelje na IBM-ovim vlastitim poslužiteljskim proizvodima;
- IBM Tivoli Web Site Analyzer- analizirati promet posjetitelja, statistiku posjećenosti stranice, cjelovitost sadržaja web stranice;
- IBM Tivoli savjetnik za razinu usluge- osigurati prediktivnu kontrolu i predviđanje kvarova kroz kvantitativnu analizu učinka;
- IBM Tivoli NetView- za upravljanje mrežom;
- IBM Tivoli Switch Analyzer- otkriti i popuniti sve sklopke mrežnog sloja;
- IBM Tivoli Enterprise Console- za višerazinsko rješavanje problema i analizu događaja.
Osim toga, postoji niz rješenja za automatizirano upravljanje raspodjelom IT resursa i vršnim opterećenjima.
Obitelj Tivoli također uključuje sigurnosne proizvode:
- IBMDirectory poslužitelj- za sinkronizaciju sigurnosnih podataka u svim aplikacijama koje se koriste;
- IBM Directory Integrator- integrirati identifikacijske parametre sadržane u imenicima, bazama podataka, sustavima suradnje i poslovnim aplikacijama;
- IBM Tivoli Identity Manager i IBM Tivoli Access Manager za operativne sustave- kontrolirati pristup aplikacijama i operativnim sustavima;
- IBM Tivoli Risk Manager- za centralizirano upravljanje zaštitom mreže.
Osim toga, obitelj Tivoli uključuje širok raspon proizvoda za sigurnosno kopiranje i upravljanje pohranom.
Microsoft
Iako Microsoft danas nije tržišni lider u alatima za upravljanje IT infrastrukturom, alati za upravljanje aplikacijama ove tvrtke u našoj zemlji imaju široku primjenu.
Glavna svrha alata Microsoft Microsoft Systems Management Server (SMS) i Microsoft Operations Manager (MOM), kao i administrativnih alata dostupnih korisnicima najnovijih verzija operacijskih sustava Microsoft poslužitelja (kao što su usluge automatizirane implementacije, usluge daljinske instalacije , Microsoft Group Policy Management Console, Microsoft Windows Update Services), - upravljanje softverom, automatska instalacija Microsoftovih operativnih sustava i aplikacija dizajniranih za njih, automatska isporuka ažuriranja, kontrola pristupa i prava korisnika (Sl. 5).

Riža. 5. Upravljanje informacijskim sustavima korištenjem Microsoft Operations Managera i Microsoft Systems Management Servera
Microsoft Systems Management Server je dizajniran da osigura automatsku distribuciju i obračun softvera u velikim distribuiranim sustavima temeljenim na operativnim sustavima samog Microsofta, uključujući planiranje uz određivanje hardvera i softvera u lokalnoj mreži, provjeru, analizu, implementaciju poslovnih aplikacija za različite ciljne skupine korisnika , instalacija aplikacija na novonastalim poslovima prema korisničkim pravima. Ovaj proizvod omogućuje ciljanu instalaciju različitog softvera za različite korisničke skupine, kao i rješavanje problema vezanih uz inventar softvera i nadzor nad korištenjem softverskih i hardverskih resursa prikupljanjem informacija o softverskim proizvodima i opremi instaliranoj na mreži te o njihovom korištenju.
Microsoft
Microsoft Operations Manager dizajniran je za prepoznavanje i rješavanje problema s mrežom, hardverom i aplikacijama izravnim praćenjem tekućih događaja, kao i statusa i performansi mrežnih resursa, te izdavanjem upozorenja o potencijalnim problemima (Slika 6).

Riža. 6. Praćenje statusa poslužitelja pomoću Microsoft Operations Managera
Proizvod je dizajniran za upravljanje IT infrastrukturom malih tvrtki ili specijaliziranih grupa poslužitelja (do 10 kom.). Microsoft Operations Manager 2005 Workgroup Edition. Omogućuje prepoznavanje potencijalnih opasnosti u radu softvera te uz ugrađene alate za analizu spriječiti njihovu eskalaciju u ozbiljne probleme, poboljšati učinkovitost IT operacija, pojednostaviti podršku za heterogene platforme i aplikacije te kreirati vlastite servisne pakete.
Osim toga, postoje zasebna rješenja za upravljanje performansama i analizu događaja za komponente IT infrastrukture temeljene na Microsoftovim poslužiteljskim proizvodima, kao što su Active Directory Management Pack- za praćenje statusa imeničke usluge Active Directory, Exchange Management Pack- za upravljanje uslugama razmjene poruka i pohranama podataka Exchange, kao i brojnim drugim proizvodima. Kako bi se osigurala interoperabilnost s alatima za upravljanje IT infrastrukturom trećih strana, dostupan je proizvod Okvir konektora MOM, koji omogućuje dvosmjerno emitiranje upozorenja i sinkronizaciju podataka korištenjem web usluga.
upravljanje IB-om
- Cobit - "ciljevi kontrole za informacijske i srodne tehnologije"
- Pročitajte odjeljak 1
- Pročitajte odjeljak 1
- Pročitajte odjeljak 1
- Pročitajte odjeljak 1
Standard Ciljevi kontrole za informacijske i srodne tehnologije (CobiT), sada u svom trećem izdanju, pomaže u rješavanju višestrukih potreba kontrole povezujući poslovni rizik, zahtjeve kontrole i tehnička pitanja. To vam omogućuje da formirate dobru praksu upravljanja IT-om u svim grupama procesa u okviru standarda, kao i da opišete vrste IT aktivnosti u obliku upravljane i logično izgrađene strukture. “Dobra praksa” CobiT-a konsenzus je stručnih savjeta koji pomažu optimizirati ulaganja u IT i pružaju skup metrika za usmjeravanje u slučaju nužde.
Temeljni koncept CobiT-a je da IT kontrola razmatra informacije kao proizvod koji je neophodan za podršku poslovnim ciljevima ili zahtjevima i kao rezultat kombinirane upotrebe IT-a i povezanih resursa kojima upravljaju IT procesi.
CobiT Standard uključuje sljedeće serije knjiga:
1. Sažetak za smjernice.
2. Osnove.
3. Ciljevi kontrole (detaljni ciljevi - 318 komada)
4. Vodič za upravljanje.
5. Smjernice za reviziju.
6. Načini provedbe.

CobiT standard identificira 34 IT procesa, grupirana u sljedeće četiri skupine (slika 1.1):
1. Planiranje i organiziranje - procesi koji obuhvaćaju strategiju i taktiku, kao i određivanje načina na koji će razvoj IT-a najbolje doprinijeti ostvarenju poslovnih ciljeva.
2. Akvizicija i implementacija - procesi koji obuhvaćaju razvoj i akviziciju IT rješenja koja moraju biti integrirana u poslovni proces. Promjena postojećih sustava.
Cobit - "ciljevi kontrole za informacijske i srodne tehnologije"
3. Rad i održavanje - procesi koji zapravo pružaju potrebne usluge.
4. Kontrola - procesi menadžerskog nadzora i neovisne evaluacije koji uključuju unutarnju i vanjsku reviziju ili druge izvore.
Za svaki od 34 IT procesa definiran je jedan cilj kontrole razine IT procesa (namjera ili željeni rezultat koji se postiže provedbom kontrolnih postupaka u IT aktivnostima). Ovi ciljevi kontrole dalje su raščlanjeni na detaljne ciljeve kontrole. U standardu CobiT postoji 318 takvih detaljnih ciljeva.

Slika 1.1. IT obrađuje CobiT
Prema CobiT-u, IT procesi se koriste za ispunjavanje sljedećih 7 informacijskih zahtjeva (djelomično se preklapaju).
1. Korisnost - informacija je relevantna i u skladu s BP-om, dostavljena na vrijeme, dosljedna i upotrebljiva.
2. Učinkovitost – pružanje informacija temeljeno na optimalnom korištenju resursa.
3. Povjerljivost - zaštita podataka od neovlaštenog pristupa.
4. Integritet - točnost i potpunost informacija u skladu s poslovnim vrijednostima i očekivanjima.
5. Dostupnost - informacije su dostupne na zahtjev osobe s BPD-om sada iu budućnosti.
6. Sukladnost - usklađenost sa zahtjevima zakonodavstva, regulatornih tijela i ugovornih obveza kojima BP podliježe.
7. Integritet – pružanje menadžmentu potrebnih informacija za upravljanje i ispunjavanje odgovornosti organizacije u vezi s financijskim aktivnostima i izvješćivanjem regulatorima.
Cobit - "ciljevi kontrole za informacijske i srodne tehnologije"
Ciljevi kontrole IT procesa mogu zadovoljiti gore navedene informacijske zahtjeve i biti primarni ili sekundarni.
CobiT također definira IT resurse uključene u ispunjavanje gore navedenih informacijskih zahtjeva. Postoji 5 klasa IT resursa:
1. Podaci - informacijski objekti u širem smislu, uključujući nestrukturirane, grafiku, zvuk.
2. Aplikacije - skup ručnih i softverskih postupaka.
3. Tehnologija - hardver, OS, DBMS, mreže, multimedija, itd.
4. Infrastruktura - svi resursi za hosting i podršku IP-u.
5. Osoblje - uključuje osoblje i njegove vještine, svijest i sposobnost planiranja, organiziranja, nabave, opskrbe, održavanja i kontrole IS-a i usluga.
Ciljevi upravljanja IT procesima, njihov odnos sa zahtjevima za informacijama i IT resursima prikazani su na slici 1.2.

Slika 1.2. Ciljevi kontrole IT procesa
Stoga su za svaki kontrolni cilj definirani glavni i sekundarni informacijski zahtjevi koje podržavaju. Također se utvrđuje koji su resursi uključeni u ispunjavanje ovih zahtjeva.
Knjiga CobiT "Management Guide" uvodi model stupnja razvijenosti procesa organizacije s ocjenom stupnja razvijenosti od 0 (ne postoji) do 5 (optimizirano). Ovaj model zrelosti dalje se koristi prilikom provođenja revizija IT procesa i odgovora na pitanje u kojoj mjeri IT procesi ispunjavaju potrebne zahtjeve. S ove točke gledišta CobiT ima dobre dodirne točke s ruskim bankarskim standardom.
U CobiT-u se KPI-jevi unose za svaki od 34 procesa. Oni definiraju mjerila koja ex post signaliziraju menadžmentu da IT proces ispunjava poslovne zahtjeve. Ta se mjerila obično izražavaju u smislu zahtjeva za informacijama kao što su:
Cobit - "ciljevi kontrole za informacijske i srodne tehnologije"
Dostupnost informacija potrebnih za zadovoljenje poslovnih potreba.
Nema rizika za integritet ili povjerljivost.
Profitabilnost procesa i poslovanja.
Potvrda pouzdanosti, korisnosti i usklađenosti sa zahtjevima.
Za svaki od 34 procesa upisani su ključni pokazatelji uspješnosti – koji pokazuju koliko dobro IT proces obavlja svoje funkcije i služi za postizanje svojih ciljeva. Oni su glavni pokazatelji koliko se zadani ciljevi uopće mogu ostvariti, kao i dobri pokazatelji postojećih sposobnosti, praksi i vještina.
Za svaki od 34 IT procesa definirana je kvalitativna ljestvica (0-5) koja pokazuje u kojem slučaju proces treba pripisati određenom modelu razvojne razine.
U CobiT knjizi „Audit Guide“ za svaki od 34 procesa određeno je kako se procjenjuje stupanj njegove usklađenosti s utvrđenim zahtjevima. Za svaki od njih definirani su:
1. Osobe organizacije koje treba intervjuirati tijekom revizije.
2. Informacije i dokumenti koje treba dobiti od ispitanika.
3. Čimbenici koji se procjenjuju (vrsta upitnika).
4. Čimbenici koji se ispituju (provjeravaju).
Knjiga CobiT Implementation Techniques govori o tome na koga treba utjecati da implementira COBIT u organizaciji te daje akcijski plan za implementaciju COBIT-a. Daju se upitnici za osoblje koje se koristi u fazi implementacije, za internu procjenu korporativnog IT upravljanja, internu dijagnostiku upravljanja. Dati su obrasci za reviziju i procjenu rizika.
Promjena poslovnih pogleda na pružanje IT usluga dovodi do potrebe implementacije procesa upravljanja njihovom dostupnošću.
U trećoj verziji ITIL-a procesi za upravljanje dostupnošću i kontinuitetom IT usluga razmatraju se zajedno (u daljnjem tekstu proces). Najvažniji ključni koncepti ovog procesa suradnje su:
dostupnost- sposobnost informatičke usluge ili njezinih sastavnica da obavljaju svoje funkcije u određenom vremenskom razdoblju;
pouzdanost- sposobnost IT usluge ili njezinih komponenti da obavljaju određene funkcije u određenim radnim uvjetima;
nadoknadivost- sposobnost IT usluge ili njezinih komponenti da povrate svoje operativne karakteristike koje su djelomično ili potpuno izgubljene kao rezultat kvara;
održivost- karakteristika IT komponenti koja određuje njihovu lokaciju i parametre kako bi se osigurala racionalnost radnji osoblja tijekom instalacije, transporta, održavanja i popravka (ovaj koncept se odnosi na vanjske pružatelje IT usluga).
Posao ima vlastitu predodžbu o dostupnosti i cijeni IT usluga koje su mu potrebne, stoga je cilj procesa osigurati potrebnu razinu dostupnosti uz zadržavanje određene razine troškova. Kako bi se postigao ovaj cilj, proces ima za cilj izvršiti sljedeće zadatke:
Planiranje i razvoj IT usluga, uvažavajući poslovne zahtjeve za razinom dostupnosti;
Optimiziranje dostupnosti IT usluga kroz ekonomična poboljšanja;
Smanjenje broja i trajanja incidenata koji utječu na dostupnost IT usluga.
U tijeku rješavanja ovih problema fiksiraju se poslovni zahtjevi za dostupnošću IT usluga i komponenti IT infrastrukture; izrađuju se potrebna izvješća; Razine dostupnosti IT usluga povremeno se preispituju; formira se plan dostupnosti koji definira prioritete i odražava mjere za poboljšanje dostupnosti IT usluga. Drugim riječima, proces se svodi na planiranje isporuke IT usluga, mjerenje razine dostupnosti i poduzimanje radnji za njeno poboljšanje.
Planiranje
Prilikom planiranja formulira se formulacija poslovnih zahtjeva za dostupnost IT usluga, razvijaju se kriteriji za određivanje razine dostupnosti i prihvatljivog vremena zastoja IT usluga, te se razmatraju i neki aspekti informacijske sigurnosti. Posao mora uspostaviti granicu koja definira dostupnost i nedostupnost IT usluge, kao što je dopušteno vrijeme zastoja za IT uslugu u slučaju kvara u IT infrastrukturi.
Prilikom projektiranja dostupnosti IT usluga provodi se analiza IT infrastrukture kako bi se utvrdile najranjivije komponente koje nemaju redundanciju i koje u slučaju kvara mogu negativno utjecati na pružanje IT usluge. U terminologiji ITIL-a takve se komponente nazivaju Single Point of Failure (SPOF), a za njihovo određivanje koristi se metoda Component Failure Impact Analysis (CFIA). Ova se metoda koristi za procjenu i predviđanje utjecaja kvarova IT komponenti na IT uslugu. Glavni ciljevi CFIA-e su:
Identificirati točke kvara koje utječu na dostupnost;
Analiza utjecaja kvara komponente na poslovanje i korisnike;
Utvrđivanje odnosa komponenti i osoblja;
Određivanje vremena oporavka komponenti;
Definirajte i dokumentirajte opcije oporavka.
Za analizu rizika koristi se metoda analize i upravljanja rizicima (CCTA Risk Analysis and Management Method, CRAMM) u kojoj se analiziraju moguće prijetnje i ovisnosti IT komponenti te se procjenjuje vjerojatnost nastanka nestandardnih situacija ili izvanrednih događaja. .
Kako bi se osigurala potrebna razina dostupnosti, moguće je koristiti tehnike maskiranja od negativnog utjecaja zbog planiranog ili neplaniranog prekida rada komponente, dupliciranja IT komponenti, kao i korištenje sredstava za poboljšanje performansi komponente u slučaju povećanje opterećenja itd. U slučajevima kada određene poslovne funkcije uvelike ovise o dostupnosti IT usluga, a goodwill od zastoja se smatra neprihvatljivim, postavljaju se više vrijednosti dostupnosti za određene IT usluge i alociraju se dodatni resursi.
Dizajn isporuke IT usluga osigurava ispunjavanje navedenih zahtjeva dostupnosti, ali to se odnosi na stabilno, operativno stanje IT usluga. No, mogući su i kvarovi, stoga se također provodi planiranje obnove IT usluga, uključujući organizaciju interakcije s procesom upravljanja incidentima i servisom Service Desk; planiranje i implementacija nadzornih sustava za detekciju kvarova i pravovremenu dojavu o njima; razvoj zahtjeva za backup i oporavak hardvera, softvera i podataka; razvoj strategije sigurnosnog kopiranja i oporavka; definicija metrike oporavka, itd.
Drugi aspekt planiranja je određivanje vremena zastoja. Sve IT komponente trebale bi podlijegati strategiji održavanja. Ovisno o IT-u koji se koristi te kritičnosti i važnosti poslovnih funkcija koje podržava određena IT komponenta, učestalost i razina usluge mogu varirati. Ukoliko je potrebno pružati uslugu u 24x7 modu, potrebno je pronaći optimalnu ravnotežu između zahtjeva za servisiranjem IT komponenti i poslovnih gubitaka od zastoja usluge. Odobreni rasporedi usluga trebaju biti dokumentirani u Ugovorima o razini usluge (SLA).
Poboljšanje dostupnosti IT usluga
Zašto poboljšati pristupačnost? Razlozi mogu biti brojni: neusklađenost kvalitete IT usluga sa zahtjevima SLA; nestabilnost u pružanju IT usluga; trend pada dostupnosti IT usluga; neprihvatljivo dugo vrijeme oporavka; zahtjeve poduzeća za povećanjem razine dostupnosti.
Poboljšanje dostupnosti zahtijeva razumne dodatne financijske troškove, a za utvrđivanje mogućnosti poboljšanja IT usluga koriste se određene metode i tehnologije, uključujući analizu stabla grešaka (Fault Tree Analysis, FTA) i analizu zastoja sustava (Systems Outage Analysis, SOA).
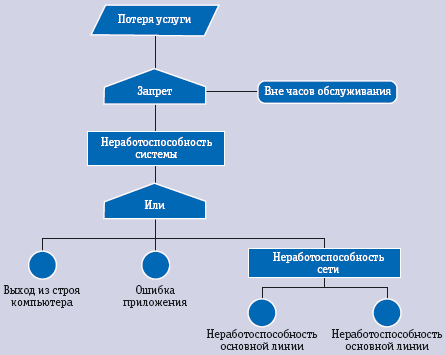
Analiza stabla grešaka identificira lanac događaja koji dovode do kvara IT komponente ili IT usluge. Grafički, stablo kvarova (vidi sliku) je slijed događaja koji počinje početnim događajem, nakon kojeg slijedi jedan ili više funkcionalnih događaja, a završava konačnim stanjem. Ovisno o događajima, nizovi se mogu logično granati.
Analiza ispada sustava je strukturirani pristup identificiranju temeljnih uzroka prekida u pružanju IT usluga i koristi više izvora podataka za određivanje lokacije i uzroka prekida. Ciljevi ove analize su:
Identifikacija temeljnih uzroka kvarova u pružanju IT usluga;
Utvrđivanje učinkovitosti IT servisne podrške;
Izrada izvješća;
Pokretanje programa za provedbu prihvaćenih preporuka;
Analiza poboljšanja dostupnosti dobivena analizom zastoja sustava.
Korištenje analize zastoja sustava poboljšat će dostupnost bez povećanja troškova, poboljšati vlastite vještine i sposobnosti osoblja kako bi se izbjegli troškovi savjetovanja o poboljšanju dostupnosti te odrediti određeni program poboljšanja.
Rezultat aktivnosti poboljšanja dostupnosti usluga je dugoročni plan za proaktivno poboljšanje dostupnosti IT usluga unutar financijskih ograničenja. Plan dostupnosti opisuje trenutnu i planiranu razinu dostupnosti, kao i aktivnosti koje je potrebno provesti kako bi se ona poboljšala. U pripremi plana potrebno je sudjelovanje poslovnih predstavnika, voditelja implementiranih ITSM procesa, predstavnika vanjskih pružatelja IT usluga, stručnjaka tehničke podrške zaduženih za testiranje i održavanje. Plan se izrađuje za razdoblje do dvije godine, a za sljedećih šest mjeseci trebao bi sadržavati detaljan opis aktivnosti. Plan se revidira tromjesečno uz minimalne prilagodbe i svakih šest mjeseci uz mogućnost većih izmjena.
Mjerenje dostupnosti IT usluga
IT usluga se može smatrati dostupnom sa stajališta korisnika kada vitalne poslovne funkcije koje je koriste rade normalno. Pritom su glavni kvantitativni pokazatelji dostupnost - omjer vremena stvarne dostupnosti IT komponente prema vremenu dostupnosti definiranom u ugovorima o razini usluge te nedostupnost (u %) - inverzija dostupnosti. Ove parametre koriste IT usluge i nisu baš reprezentativni s poslovne točke gledišta jer ne odražavaju poslovne ili korisničke vrijednosti dostupnosti - mogu pokazati visoku razinu dostupnosti IT komponenti, dok stvarna razina dostupnosti IT usluge će biti niske.
Pokazatelji kao što su učestalost ispada IT usluge, ukupno trajanje ispada, područje utjecaja prekida IT usluge mogu biti razumljivi poslovanju.
Uloge i odgovornosti
Unutar procesa definirana je uloga voditelja procesa čija je odgovornost da upravlja procesom i provodi potrebne radnje. Voditelj procesa odgovoran je za rad i razvoj procesa u skladu s propisima i planovima. Za ulogu voditelja procesa preporuča se prihvatiti djelatnika koji ima praktično iskustvo u upravljanju procesima, poznaje ITSM, statističke i analitičke metode koje se koriste u IT-u, principe upravljanja troškovima, ima iskustva u radu s osobljem, zna pregovarati, ima iskustva u radu s osobljem, zna pregovarati. itd.
Implementacija procesa
Implementacija bilo kojeg ITSM procesa je dug i složen projekt s određenim ciljevima i rokovima. Samostalna implementacija je teška: implementacija procesa paralelna sa svakodnevnim operacijama ne dopušta vam da se potpuno usredotočite na projekt; konstantno “povlačenje” resursa na zadatke izvan projekta u konačnici dovodi do povećanja financijskih troškova, pomicanja vremenskog okvira projekta na neodređeno vrijeme, postupnog gubitka pažnje ili čak mogućeg zaustavljanja projekta. Osim toga, interna implementacija zahtijeva poznavanje domene, što podrazumijeva skupu obuku.
Kao i svaki projekt, implementacija procesa započinje stvaranjem projektnih timova, izradom dokumenata za upravljanje projektom, izradom projektnog plana i tako dalje. U fazi "predprojektnog" rada provode se marketinške aktivnosti kako bi se predstavnici gospodarstva upoznali s ITIL tehnologijama i preporukama te opravdala potreba poduzeća za implementacijom procesa upravljanja dostupnošću IT usluga.
Nakon dogovora i dobivenog pozitivnog odgovora o provedbi procesa, utvrđuju se ciljevi i granice predmetnog područja procesa.
Učinak i problemi
Primarni učinak implementacije procesa je da su IT usluge dizajnirane imajući na umu dostupnost, te da se njima upravlja i upravlja na dogovorenoj razini dostupnosti i cijene. Pozitivni faktori su također: prisutnost jedne osobe odgovorne za dostupnost IT usluga; optimalno korištenje performansi IT infrastrukture kako bi se osigurala potrebna razina dostupnosti IT usluga; smanjenje učestalosti i trajanja kvarova IT usluga tijekom vremena; kvalitativni prijelaz u aktivnostima pružatelja IT usluga od otklanjanja grešaka u pružanju usluga do povećanja razine njihove dostupnosti.
Mogući problemi koji mogu negativno utjecati na odluku o implementaciji i vođenju procesa obično su organizacijske prirode:
Prisutnost situacije u kojoj je svaki IT voditelj odgovoran za dostupnost IT sustava ili komponenti pod njegovom odgovornošću, dok se ukupna dostupnost IT usluga ne prati i može biti nezadovoljavajuća;
Neuspjeh u implementaciji procesa jer se trenutna dostupnost IT usluga smatra prihvatljivom;
Pretpostavke da će se, ako postoje drugi implementirani ITSM procesi, proces upravljanja dostupnošću izvoditi automatski;
Otpor centralizaciji u upravljanju IT infrastrukturom od strane IT menadžera;
Nedovoljan autoritet voditelja procesa, što dovodi do nemogućnosti pravilnog obavljanja dužnosti.
Evgeny Bulychev ( [e-mail zaštićen]) - konzultant odjela I-Teco Business Consulting (Moskva).