IT-teenuste kättesaadavus on väga oluline. Kui kliendi poolt nõutavad teenused ei ole kättesaadavad, on ta rahulolematu. Miks peaks klient maksma teenuse eest, mis pole tegelikult saadaval, kui ta seda vajab? Seetõttu sisaldub KPI-des sageli ka teenuse kättesaadavuse kokkulepitud mõõdik.
IT-töötajad näevad palju vaeva, et püstitatud eesmärk oleks täidetud ja näitavad klientidele aruannetes numbreid, mis seda kinnitavad. Tavaliselt kasutavad IT-firmad selleks protsente, näiteks 99,999%. Kahjuks tähendab see sageli, et nad keskenduvad vaid protsentidele ja kaotavad silmist oma tegeliku eesmärgi – pakkuda kliendile väärtust.
Probleem saadavuse protsentides
Üks lihtsamaid viise saadavuse arvutamiseks põhineb kahel osal. Lepite kokku ajavahemikes, mille jooksul teenus peaks olema saadaval aruandlusperiood. See on kokkulepitud teenindusaeg (AST). Sel perioodil mõõdate seisakuaega (DT). Lahutage seisakuaeg kokkulepitud teenuse kättesaadavuse ajast ja muutke see protsendiks.
Kui AST on 100 tundi ja seisakuaeg on 2 tundi, on saadavus:

Probleem on selles, et kuigi see arvutus on üsna lihtne, nagu ka andmete kogumine selle jaoks, pole tegelikult selge, millist näitajat arvutuse tulemusel saadud arv täpselt kujutab. Ma räägin sellest veidi hiljem.
Veelgi hullem, kui kliendi vaatevinklist vaadatuna saad suhelda, et oled saavutanud kokkulepitud eesmärgid, jättes kliendi täiesti rahulolematuks.
Mõtetava saadavuse aruanne peaks põhinema mõõtmistel, mis kirjeldavad kliente huvitavaid asju, näiteks e-kirjade saatmise ja vastuvõtmise või sularahaautomaadist sularaha väljavõtmise võimalust, ning üldine protsent ilmselt ei saa.
Juurdepääsetavuse sihtmärkide määramine
Kui soovite mõõta, dokumenteerida ja teavitada saadavust viisil, mis on teie organisatsioonile ja klientidele kasulik, peate tegema kahte asja. Esiteks määratlege kontekst ja tugevdage "juurdepääsetavuse" tähendust enda ja oma klientide jaoks. Selleks peate nendega rääkima.
Teiseks peate hoolikalt läbi mõtlema mitmed praktilised küsimused: mida mõõdate, kuidas andmeid kogute, kuidas tulemusi dokumenteerite ja raporteerite.
Suhtlemine klientidega
Enne mis tahes toimingu tegemist peate mõistma, mis on teie klientide jaoks oluline ja millist mõju avaldab saadavuse kaotus neile. See võimaldab teil seada realistlikke eesmärke, mis võtavad arvesse tehnoloogilisi, eelarvelisi ja personalipiiranguid.
Aga mida täpselt peaksite oma klientidele ütlema? Suurepärane Alguspunkt sest vestlus võib muutuda seisaku mõjuks. Allpool on viis küsimust, mida peaksite küsima:
- Millised ärifunktsioonid on kriitilise tähtsusega ja seisakuaja kaitseks kõige olulisemad?
- Kuidas seisakud äritegevust mõjutavad?
- Kuidas seisakute sagedus äritegevust mõjutab?
- Millist mõju avaldab seisak organisatsiooni tulemuslikkusele?
- Nagu need sunnitud seisakud tajuvad organisatsiooni kliendid?
Kriitilised ärifunktsioonid
Enamik IT-teenuseid toetab mitut äriprotsessi, millest mõned on kriitilised ja teised vähemtähtsad. Näiteks võib sularahaautomaat toetada sularaha väljastamist ja tšeki printimist. Võimalus jagada sularaha ülioluline, kuigi tšeki printimise puudumisel on palju väiksem mõju.
Peate klientidega rääkima ja otsustama, kui olulised on erinevad funktsioonid ettevõtte jaoks. Saate luua tabeli, mis loetleb kõigi nende funktsioonide seisakuaja ärimõjud. Näide:
Tabel 1 – Teenuste tähtsus protsentides
NB: numbrite summa ei tohi olla 100%
Sellest tabelist on näha, et seda teenust see pole üldse oluline, kui e-kirju pole võimalik saata ja vastu võtta, ja selle väärtus väheneb pooleni normaalsest tasemest, kui avalikke kaustu ei saa lugeda. See käsib IT-l keskenduda postiteenuse kvaliteedile.
Seisakute kestus ja sagedus
Peate välja selgitama, kuidas mõjutab kliendi äritegevust seisakute sagedus ja kestus.
Olen juba maininud, et protsentuaalne kättesaadavus ei pruugi olla piisav. Kui teenusel, mis peaks olema saadaval 100 tundi, on 98% saadavus, näitab see, et seisakuid on olnud kaks tundi. Kuid see võib tähendada kas ühte kahetunnist intsidenti või mitut lühemat juhtumit. Ühe pika intsidendi või lühikeste vahejuhtumite jada suhteline mõju sõltub äritegevuse ja äriprotsesside olemusest.
Näiteks arveldust, mis kestab kaks päeva ja mis tuleb pärast mis tahes riket uuesti käivitada, mõjutab iga lühike katkestus tõsiselt, kuid üks kauakestev sunnitud katkestus võib olla palju väiksema tähtsusega. Teisalt ei pruugi üheminutiline katkestus veebipoe tööd kuidagi mõjutada, kuid kahe tunni möödudes võib see kaasa tuua olulise klientide kaotuse. Kui teil on ettekujutus seisakute tõenäolisest mõjust teie ettevõttele, saate luua palju rohkem tõhus infrastruktuur, rakendusi ja protsesse, mis klienti tõeliselt aitavad.
Siin on näide sellest, kuidas saadavust saab mõõta ja dokumenteerida, et kajastada asjaolu, et seisakuaja mõju on erinev.
Tabel 2 – Reisi kestus ja maksimaalne sagedus
Kui kasutate sellist tabelit seisakute sageduse ja kestuse arutamisel klientidega, on need numbrid tõenäoliselt palju kasulikumad kui saadavuse protsent ja need on teie klientide jaoks kindlasti olulisemad.
Seisakud ja jõudlus
Mainin, et protsentuaalne saadavus ei ole väga kasulik klientidega seisakute sageduse ja kestuse teemal suhtlemisel. Teisest küljest, kui arutate seisakuaja mõju jõudlusele, võivad protsendid olla väga kasulikud.
Enamik intsidente ei põhjusta kõigi kasutajate teenuse täielikku kaotust. Mõnda kasutajat see ei pruugi mõjutada, samas kui teised on täielikult keelatud. Võib-olla on ainult üks katkise arvutiga kasutaja, kes ei pääse ühelegi teenusele juurde. Võite isegi liigitada selle 100% teenuse kadumiseks, kuid see oleks täiesti saavutamatu eesmärk IT jaoks ja see ei saa olla ligipääsetavuse õiglane mõõde.
Teisest küljest võite öelda, et teenus on saadaval seni, kuni keegi teine sellele juurde pääseb. Siiski pole vaja palju kujutlusvõimet, et aru saada, kuidas kliendid end tunneksid, kui teenus oleks loendis saadaval, kui paljud inimesed lihtsalt ei saa seda kasutada.
Üks viis mõju määramiseks on arvutada kaotatud kasutajaminutite protsent. Selleks tehke järgmist.
- Arvutage potentsiaalse kasutaja minutid. See on ajaühikus töötavate kasutajate koguarv. Näiteks kui teil on 10 töötajat, kes töötavad 8 tundi, on PotentialUserMinutes 10 x 8 x 60 = 4800
- Arvutage UserOutageMinutes. See on töövõimetute kasutajate koguarv korrutatuna töövõimetuse ajaga. Näiteks kui intsident takistas 5 töötajal 10 minutit töötada, on UserOutageMinutes 50.
- Arvutage kättesaadavuse protsent, kasutades väga sarnast valemit, mida nägime varem.
Ülaltoodud näites saime järgmise juurdepääsetavuse:

Sama metoodika abil saate arvutada kõnekeskuses kaotatud VoIP-i saadavuse mõju PotentialAgentPhoneMinutes ja LostAgentPhoneMinutes; tehingute või tootmisega tegelevate rakenduste puhul saate kasutada sarnast lähenemisviisi juhtumi ärimõju kvantifitseerimiseks. Võrdlete tehingute arvu, mida oleks oodanud ilma seisakuta, tegelike tehingute arvuga või eeldatava ja tegeliku toodangu hulgaga.
Kättesaadavuse mõõtmine ja aruandlus
Kui olete juurdepääsetavuseesmärgid kokku leppinud ja dokumenteerinud, peate mõtlema ligipääsetavuse mõõtmise ja aruandluse praktilistele aspektidele. Näiteks:
- Mida mõõdate?
- Kuidas te andmeid kogute?
- Kuidas te oma tulemusi dokumenteerite ja edastate?
Mida sa mõõtsidIolla
Väga oluline on mõõta ja teavitada saadavust samadel tingimustel, mis määratlevad klientidega kokkulepitud eesmärgid ja mis põhinevad ühisel arusaamal sellest, mis on kliendi juurdepääsetavus. Eesmärgid peaksid olema tema jaoks mõistlikud ja tagama, et IT-alased jõupingutused on suunatud tema äritegevuse toetamisele.
Tavaliselt on need eesmärgid osa IT ja kliendi vahelisest teenusetaseme lepingust (SLA), kuid peate olema ettevaatlik, et SLA numbrid ei muutuks teie eesmärgiks. Teie tegelik eesmärk on pakkuda teenuseid, mis vastavad teie klientide ootustele.
Kuidas andmeid koguda
IT-teenuste kättesaadavuse kohta andmete kogumiseks on palju erinevaid viise. Mõned neist on lihtsad, kuid mitte väga täpsed, mõned on üsna kallid. Oma aruannete loomiseks saate kasutada ainult ühte lähenemisviisi või kombineerida neid mitut.
Andmete kogumine tehnilises toes
Üks võimalus saadavusandmete kogumiseks on kasutajatoe kaudu. Tavaliselt määravad teenindajad iga juhtumi mõju ja kestuse ettevõttele, kuna see on osa juhtumite haldamisest. Neid andmeid saab hästi kasutada vahejuhtumite kestuse ja mõjutatud kasutajate arvu määramiseks.
See meetod on tavaliselt üsna odav. See võib aga kaasa tuua vaidlusi kättesaadavusandmete täpsuse üle.
Infrastruktuuri ja rakenduste saadavuse mõõtmine
See lähenemisviis sisaldab tööriistakomplekti kõigi teenuse osutamiseks vajalike komponentide jaoks ja saadavuse arvutust, mis põhineb arusaamal, kuidas iga komponent oma panuse annab.
See võib olla väga tõhus, kuid see võib jätta vahele väikesed avariid. Näiteks võib väike andmebaasi rikkumine takistada mõnel kasutajal teatud tüüpi tehinguid sooritamast. See meetod võib ka tavaliste komponentide mõju märkamata jätta, näiteks üks minu klientidest ei töötanud regulaarselt Meil nende peakorteri ebausaldusväärsete DHCP-serverite tõttu, kuid IT ei loginud seda e-posti seisakuna.
Fiktiivsed kliendid
Mõned ettevõtted kasutavad näidikliente teadaolevate tehingute saatmiseks võrgu teatud punktidest, et kontrollida saadavust.
Tegelikult on see täieliku kättesaadavuse mõõt. Sõltuvalt võrgu suurusest ja keerukusest võib selle lähenemisviisi rakendamine olla üsna kulukas ja see annab teada ainult konkreetsete näilike klientide saadavusest. See tähendab, et väikesed tõrked võivad jääda märkamata, näiteks kui intsident põhjustas teatud veebibrauseri ebaõige töö, samas kui näiv klient kasutab teist brauserit.
Seda andmekogumist toetavad tööriistad teatavad sageli ka teenuse tõhususest ja saadavusest, mis võib olla kasulik täiendus.
Rakenduste arendamine
Mõned ettevõtted lisavad oma rakendusi spetsiaalne kood täieliku kättesaadavuse jälgimiseks. See aitab realistlikult mõõta teenuste täielikku kättesaadavust, eeldusel, et see eesmärk seati rakenduse arendamise ajal. Reeglina sisaldab see täpsustus koodi nii klientrakenduses kui ka serveriosas.
Kui see on hästi rakendatud, saab see mitte ainult koguda saadavuse andmeid, vaid aidata ka täpselt kindlaks teha, kus tõrge ilmnes, mis võib aidata parandada saadavust, vähendades intsidentide lahendamiseks kuluvat aega.
Kuidas oma leide dokumenteerida ja edastada
Kui olete kättesaadavuse andmed kogunud, peate mõtlema, kuidas tulemusi oma klientidele edastada.
Planeerige seisakuid
Käideldavuse mõõtmise ja aruandluse üks aspekt, mida sageli tähelepanuta jäetakse, on seisakud. Kui te ei arvesta saadavuse aruannete koostamisel kavandatud seisakuid, on oht, et kaasate mõõdikuid, mis ei vasta tõele.
On mitmeid viise, kuidas tagada, et ajastatud seisakud ei suurendaks statistikat. Üks neist on ajastatud seisakuaeg teatud aja jooksul, mis ei sisaldu saadavuse arvutuses. Teine on plaanitud seisakuaja määramine. Näiteks ei pruugi mõned organisatsioonid arvestada tulevaseks kuu aega ette planeeritud seisakuid.
Olenemata sellest, mida otsustate teha, on oluline, et teie SLA oleks selgelt määratletud, kuidas planeeritud seisakuid arvestatakse.
Arvestusperioodi leping
Varem rääkisin piirangutest, mida protsentuaalne saadavus varjab. Sellest hoolimata kasutatakse seda ja seda kasutatakse jätkuvalt laialdaselt. Seetõttu on oluline mõista, et peate määrama ajaperioodi, mille jooksul arvutused tehakse ja aruanded esitatakse, kuna see võib olla teie aruannetes sisalduvate arvude jaoks kriitilise tähtsusega.
Mõelge näiteks IT-ettevõttele, kes on nõustunud ööpäevaringse teenuse ja 99% kättesaadavusega. Oletame, et on kaheksatunnine paus:
- kui anname teada saadavuse kord nädalas, siis AST (kokkulepitud teenindusaeg) on 24 x 7 tundi = 168 tundi
- igakuine AST (24 x 365) / 12 = 730 tundi
- kvartali AST (24 x 365) / 4 = 2190 tundi
Nende arvude lisamine saadavuse võrrandisse annab:
- Iganädalane saadavus = 100% x (168–8) / 168 = 95,2%.
- Igakuine saadavus = 100% x (730–8) / 730 = 98,9%
- Kvartali saadavus = 100% x (2190-8) / 2190 = 99,6%
Kõik need on kehtivad teenuse kättesaadavuse näitajad, kuid ainult üks neist näitab, et eesmärk on täidetud.
Vahi all
Peaaegu kõik IT-ettevõtted, kellega olen töötanud, koostavad meetmete ja aruannete oma teenuste kättesaadavuse kohta. Tõeliselt tõhusad IT-osakonnad töötavad koos klientidega, et optimeerida nende investeeringuid ja tagada suurepärane kättesaadavus. Kuid kahjuks keskenduvad paljud IT-ettevõtted SLA numbritele ega suuda oma klientide vajadusi rahuldada, isegi kui nad näitavad oma aruannetes järjekindlaid numbreid.
See on pikk artikkel, allpool on selles käsitletud põhipunktid:
- Pole vaja kliendile öelda, et tarnisite 98% saadavuse, kui te ei mõista 2% seisaku mõju
- Rääkige oma klientidega ja veenduge, et mõistate seisakute mõju neile ja lõppklientidele
- Mõelge, kuidas kaitsta oma klientide olulisi äriprotsesse
- Leidke viise, kuidas mõõta seisakute sagedust ja kestust, samuti seisakute mõju jõudlusele, mis vastavad teie klientide vajadustele
- Nõustuge, dokumenteerige ja täpsustage saadavuse mõõdikuid viisil, mis on teie klientide jaoks mõistlik ja aidake planeerida
- Kasutage saadavuse õigeks hindamiseks ja sellest teatamiseks sobivaid tööriistu.
Mida soovite veel minu nõuandele lisada? Palun kirjutage kommentaaridesse.

Teenusetaseme leping – dokument, mis kirjeldab teenuse taset, mida klient tarnijalt ootab, tuginedes sellele teenusele kohaldatavatele mõõdikutele, ning kehtestab tarnija vastutuse, kui kokkulepitud mõõdikuid ei saavutata.
Jämedalt öeldes, kui Internet on kodus välja lülitatud, siis sisse Lõpuks sülitad ja lähed jalutama, kinno või kõrtsi, parimal juhul lootes ümberarvestusele.
Kui teie ühendus kontoris katkeb, siis müük seiskub (kliendid ei pääse läbi ja posti teel vastust ootamata lähevad teiste tarnijate juurde), raamatupidamine ei saa makseid teha (siin ajate partnerid juba alt) ja kui olete näiteks kauplemisbüroo, võib kahjumi summa ulatuda tuhandetesse dollaritesse (te ei saa aktsiaid õigel ajal osta ega müüa).
Kanalite reserveerimise vms osas võib olla lüüriline kõrvalepõige, kuid meie silme ees on näide - Moskva linna kompleksi hoone, milles paar aastat tagasi osutusid nii põhi- kui ka varukanal pärit. sama pakkuja. Ja häda, nagu teate, ei tule üksi. Selle tulemusena kaks korda 7-8 tundi (in tööaeg) leidsid end Fortune 500 ettevõtetega kontaktist väljas.
Seetõttu püüavad eriti peened õigusteenused ettevõtetel, kelle äritegevus on eriti tundlik suhtluskvaliteedi suhtes, arvutada ettevõttele tekitatud kahju suurust mitte ainult kasutamata teenuste maksumuse, vaid ka kliendi suhtluse tõttu saamata jäänud kasumi järgi. seisakuid.
lähtekohad
Siin on mõned näitajad, mida ühel või teisel kujul operaatori dokumentides leidub:
ASR (vastuste konfiskeerimise suhe)- parameeter, mis määrab telefoniühenduse kvaliteedi antud suunas. ASR arvutatakse protsendina numbrile helistamise tulemusel loodud telefoniühenduste arvust kokku antud suunas tehtud kõned.
PDD (valimisjärgne viivitus)- parameeter, mis määrab aja (sekundites), mis on möödunud kõne hetkest kuni telefoniühenduse loomise hetkeni.
Teenuse saadavuse suhe- teenuse osutamise katkemise aja suhe kogu aega, mil teenust tuleks osutada.
Paketi kadumise suhe- õigesti vastuvõetud andmepakettide suhe teatud aja jooksul võrgu kaudu edastatud pakettide koguarvusse.
Ajalised viivitused teabepakettide edastamisel- teabepaketi kahe võrguseadme vahel edastamiseks kuluv aeg.
Info edastamise usaldusväärsus- ekslikult edastatud andmepakettide arvu ja edastatud andmepakettide koguarvu suhe.
Tööperioodid, abonentide teavitamise aeg ja teenuste taastamise aeg.
Teisisõnu, teenuse kättesaadavus 99,99% näitab, et operaator garanteerib mitte rohkem kui 4,3 minutit jõudeolekut kuus, 99,9% - et teenust ei pruugita osutada 43,2 minutit ja 99% - et katkestus võib kesta kauem kui 7 tundi. Mõnes praktikas on võrgu kättesaadavus piiritletud ja eeldatakse parameetri väiksemat väärtust - in töövaba aeg. peal erinevad tüübid osutatakse ka teenuseid (liiklusklassid). erinevaid tähendusi näitajad. Näiteks hääle puhul on viivituse indikaator kõige olulisem – see peaks olema minimaalne. Ja see vajab väikest kiirust, lisaks võivad mõned paketid kaduda ilma kvaliteeti kaotamata (sõltuvalt koodekist kuni umbes 1%). Andmeedastuse puhul on esikohal kiirus ja pakettide kadu peaks olema null.
Maailma standardid
Lääne praktikas on tavaks esitada ametlik aruanne võrgu parameetrite kohta Eelmisel aastal. Siin on näiteks mitmete tuntud brändide maikuu internetikanali näitajad.
Signaali edastamise viivitus (latentsus, ms)
| Sprintnet | Verizon | Kaabel ja juhtmeta | NTT | |||||
| Fakt | Standard | Fakt | Standard | Fakt | Standard | Fakt | Standard | |
| Euroopa | 18.9 | 45 | 15.178 | 30 | 17.6 | 35.0 | 24.00 | 35 |
| USA | 36.91 | 55 | 42.851 | 45 | 45.9 | 65.0 | 45.83 | 60 |
| Aasia | 83.78 | 105 | 100.640 | 125 | 48.3 | 90.0 | 47.34 | 95 |
| Euroopa Aasia | 207.63 | 270 | - | - | 174.1 | 310.0 | 260.23 | 300 |
| Euroopa-USA | 74.53 | 95 | 78.784 | 90 | 78.7 | 90.0 | 71.57 | 90 |
| Sprintnet | Verizon | Kaabel ja juhtmeta | NTT | |||||
| Fakt | Standard | Fakt | Standard | Fakt | Standard | Fakt | Standard | |
| Euroopa | 0 | 0.3% | 0.025% | 0.5% | 0 | 0.2% | 0 | 0.3% |
| USA | 0.01% | 0.3% | 0.019% | 0.5% | 0.1% | 0.2% | 0 | 0.3% |
| Aasia | 0 | 0.3% | 0.004% | 1% | 0 | 0.2% | 0 | 0.3% |
| Euroopa Aasia | 0 | 0.3% | - | - | 0 | 0.2% | 0 | 0.3% |
| Euroopa-USA | 0 | 0.3% | 0 | 0.5% | 0.1% | 0.2% | 0 | 0.3% |
| Sprintnet | Verizon | Kaabel ja juhtmeta | NTT | |||||
| Fakt | Standard | Fakt | Standard | Fakt | Standard | Fakt | Standard | |
| Euroopa | 0.0017 | 2 | 0.026 | 1 | - | - | 0 | 0.5 |
| USA | 0.0007 | 2 | 0.058 | 1 | - | - | 0 | 0.5 |
| Aasia | 0.0201 | 2 | - | - | - | - | 0 | 0.5 |
| Euroopa Aasia | 0.0001 | 2 | - | - | - | - | 0 | 0.5 |
| Euroopa-USA | 0.0001 | 2 | - | - | - | - | 0 | 0.5 |
Sprint suhtub endasse karmimalt ja kui SLA ei ole täidetud (vähemalt seoses), siis tagastatakse kliendile kogu selle kuu liitumistasu, mil probleem fikseeriti.
Kui teenus on NTT süül kättesaamatud, määrab operaator raamistiku probleemi tuvastamiseks ja lahendamiseks 15 minuti jooksul, misjärel hüvitatakse kliendile 1/30 kuni 7/30 kuumakse. Kui SLA ei vasta signaali viivituse määrale, võib klient arvestada ühekordse päevamakse tagastamisega.
Meie tegelikkus
AT Vene äri valdavalt rahvusvahelised kaubamärgid suhtuvad SLA-sse aukartusega. Samas on see väljend ise tuttavaks saanud ka pealinna klientidele ning selle dokumendi vastu tunnevad vahel huvi isegi keskmised ettevõtted. Siinkohal tahaksin märkida, et teenusetaseme leping ei asenda ega tühista teenuselepingu tüüpklausleid operaatori vastutuse kohta, samuti seadusega ja põhimäärustega kehtestatud norme (näiteks föderaalseadus " Side kohta", korraldus nr 92 "Venemaa VSS-i magistraal- ja tsoonisiseste primaarsete võrkude põhiliste digitaalkanalite ja -teede elektriliste parameetrite normide kinnitamise kohta jne), mida me kõik pühalikult järgime.
Gars Telecomi praktikas lahendatakse vaidlused mistahes "jahmatuste" korral veapiletite menetlemise ja teenuste taastamise aja raames. Teenuse ebaõnnestumise tõttu tekkinud õnnetused tuleb likvideerida 4 kuni 72 tunni jooksul (olenevalt põhjusest). Määratud parameetrite ületamise korral hüvitatakse abonendile iga täiendava seisakutunni eest ning kui operaator jõuab läviväärtusteni, suureneb hüvitise protsent.
Huvitavatest juhtumitest võib pood meelde jätta Muusikariistad, kes süüdistas meid (operaatorit) klaverimüügi kukkumises (telefon ei töötanud mõnda aega). Siin võib seda jällegi võrrelda arenenud kliendikeskse läänega, kuid parem on pöörduda Venemaa tagamaa poole, kus mitte ainult SLA osas - üldiselt pole teenuse taastamise aja mõistet olemas. Parimal juhul on reageerimisaeg 48 tundi. Näidete jaoks pole vaja isegi kaugele minna – 15 km kaugusel Peterburist – ja kohalik operaator keeldub igasugusest vastutusest. Oleks kole rääkida kõigi piirkondlike operaatorite eest, kuid kahjuks on see pigem reegel kui erand.
Milliseid järeldusi saab nendest lugudest teha?
- Pärast kaklust nad rusikatega ei vehi - kui ettevõtte jaoks on kriitilisi parameetreid, peate mõtlema, millised neist, ja arutama neid dokumentide kooskõlastamise etapis operaatoriga
- Näitaja, mille kallal peaksite pidevalt töötama, on teenuse taastamise aeg ja tehnilise toe tase. Sest kui miski ei tööta, on see hullem kui see, kui see töötab, kuid see on halb (sel juhul saab klient vähemalt kiiresti ja valutult operaatorit vahetada)
- Samuti tasub ettetellimise eest hoolitseda ja teenus peab olema sõltumatutelt operaatoritelt, kellest vähemalt üks peab olema fikseeritud.
Definitsioonid
Kõik teavad, et Microsoft Exchange'is tähendab DAG "andmebaasi saadavuse rühma" - "andmebaasi saadavuse rühma".
Andmebaas — sest tasesuur kättesaadavus serverid Exchange 2010 postkastid, määrab andmebaas, mitte server, nimelt andmebaas on see üksus, mis võib liikuda mitme serveri vahel sees andmebaasi saadavuse rühmad tõrke korral. See põhimõte on teada nagu andmebaasi teisaldatavus.
Grupp- kuna kättesaadavuse ulatus on kindlaks määratud postkasti serverid sisse DAG, mis sisse sulanud tõrkeotsingu klaster ja töötada koos rühmana.
Kättesaadavus See termin tundub olevat kõige vähem ilmne ja kõige segasem. Kummalisel kombel on sellel terminil otsene tähendus matemaatiline määratlus ja mängib olulist rolli rolli mõistmisel disaini põhimõtted Vahetus tervikuna.
Wikipedia määratleb"juurdepääs" kui tähistus üks järgmistest:
Süsteemi, alamsüsteemi või seadme kindlaksmääratud tööolekus, tõrkejuhtumis olemise määr on vähemalt teadmata, st. juhuslik aeg. Lihtsamalt öeldes, juurdepääsetavus on osa ajast, mil süsteem on olekus toimiv. Matemaatiliselt see väljendatuna 1 miinus kättesaamatus.
Koguaja suhe(d). toimiv etteantud piires intervall kuni (b) intervalli väärtus .
Kokkuleppeliselt tõenäosusteooria, tähendab see määratlus sama: tõenäosus, et see süsteem või komponent "töökorras" mis tahes meelevaldne hetk aeg .
Matemaatiliselt see saab mõõta süsteemi saadavaloleku aja loendamisega ("Uptime") mõne jaoks suur statistika esinduslik periood(tavaliselt aastad) ja jagades selle perioodi kogupikkusega. Laialdaselt aktsepteeritud terminite kasutamine keskmine aeg ebaõnnestumiste vahel (MTBF – keskmine aeg ebaõnnestumiste vahel) ja keskmine teenindusaeg (MTTR – keskmine remondiaeg)— esitleme süsteemi kättesaadavus/tõrgete vaheline aeg, süsteemi seisakud mis tahes antud ajal rike , — kättesaadavus saab väljendada kui murdosa:
Vastupidi matemaatiline tunnus on ebaõnnestumise tõenäosus:

Kättesaadavus väljendatakse sageli kui"arvu üheksa", vastavalt järgmise tabeliga:
| Kättesaadavuse tase | Kättesaadavuse väärtus | Ebaõnnestumise tõenäosus | Lubatud seisakud aastas |
| Kaks üheksat | 99% | 1% | 5256 minutit = 3,65 päeva |
| Kolm üheksat | 99.9% | 0.1% | 525,6 minutit = 8,76 tundi |
| Neli üheksat | 99.99% | 0.01% | 52,56 minutit |
| viis üheksat | 99.999% | 0.001% | 5,26 minutit |
Muidugi, juurdepääsetavuse väärtus saab olema erinev oleneb kas me arvestame planeeritud(plaaniline) ja plaaniväline (plaaniväline) seisakuaeg või ainult planeerimata seisakuid. Teenusetaseme leping (SLA), mis väljendab ärinõuded juurdepääsetavus peab sisaldama konkreetset teavet. Kuid kõigil juhtudelühe või teise olemasolu süsteem või komponent oleneb paljudest teguritest ja ülimalt oluline määratleda ja mõista need sõltuvused ja kuidas need mõjutavad kättesaadavus .
Sõltuvuste mõju saadavusele
Andmebaasi saadavus Vahetage postkaste oleneb paljude teiste olemasolust teenused ja komponendid- näiteks , ladustamise alamsüsteem,mis majutab andmebaasi, server, millel selle andmebaasi käitamine, võrguühendus see server jne. Kõik need olulised komponendid ja millegi ebaõnnestumine neist tähendab teenuse tõrget, isegi kui andmebaas ise on täiesti funktsionaalne. See tähendab et selleks, et andmebaas oleks teenusena kättesaadav, on ka iga sõltuvus peaks olema saadaval. Kui meil on õigus tuvastada ja isoleerida sõltuvuskomponendid, siis saame matemaatiliselt arvutada, kuidas need määravad tulemuseks oleva taseme andmebaasi kättesaadavus Vahetuse postkast.
Selle jaoks postkasti andmebaasid, järgmised komponendid võib pidada kriitilised sõltuvused:
ketta alamsüsteem andmebaasid / salvestussüsteem - näiteks A1 ;
postkasti server(nii riistvara kui ja tarkvarakomponendid) - A2 ;
Koos kliendi juurdepääsu server(riistvara ja tarkvara komponendid) - pidage meeles, et Exchange 2010-s on kõik kliendid ühenduvad postkasti andmebaas ainult läbi Client Access Server (Client Access rolliga server), ja oletame et CAS on paigaldatud eraldi postkasti serverid- A3 ;
võrguühendus
klientide vahel ja Client Access Server ja serveri vahel kliendi juurdepääs ja postkasti server- A4;
elektrit andmekeskuses kus serverid asuvad ja salvestussüsteemid— A5.
See nimekiri võiks jätkata… Näiteks Active Directory ja DNS esindavad ka Exchange'i jaoks kriitiline sõltuvus. Pealegi sisse lisaks puhtale tehnoloogilised sõltuvused, kättesaadavus omab mõju tegurid nagu inimlik viga, tavapäraste hooldustoimingute ebaõige teostamine, koordinatsiooni puudumine tugimeeskonnad. Kõik see võib kaasa tuua töövõimetus. Me ei proovi koosta mis tahes ammendav loetelu sõltuvused ja selle asemel keskendume sellele kuidas need üldiselt mõjutavad teenuse kättesaadavus.
Kuna need komponendid ise üksteisest sõltumatud, igaühe olemasolu on sõltumatu sündmus ja sellest tulenev andmebaasi saadavuse tase Vahetage postkaste on kombinatsioon kõik need sündmused (teisisõnu, kuni postkasti andmebaasjaoks oli saadaval kõik need kliendid komponendid peaksid saadaval). Alates tõenäosusteooria, kombinatsiooni tõenäosus iseseisvad sündmused on toode individuaalsed tõenäosused iga sündmuse jaoks:

Näiteks kui viskate kolm münti, languse tõenäosus"kotkas" kõigi kolme mündi puhul (1/2) * (1/2) * (1/2) = 1/8.
Oluline on mõista, et juurdepääsetavuse väärtus ei saa olla olla rohkem kui 1(või 100% ) ja selle tulemusena teenuse kättesaadavus on üksikute komponentide, mille juurdepääsetavuse väärtus, saadavuse korrutis rohkem ei saa kui saadavuse sõltuvuse madalaim komponent.
Seda saab illustreerida esitatud näitel järgmises tabelis(numbrid on ligikaudsed):
| Kriitiline sõltuvus | Ebaõnnestumise tõenäosus | Kättesaadavuse tase |
| Postkasti server ja salvestusruum | 5% | 95% |
| Kliendi juurdepääsu server | 1% | 99% |
| Net | 0.5% | 99.5% |
| Toit | 0.1% | 99.9% |
| 6.51383% | 95% x 99% x 99,5% x 99,9% = 93,48617% |
Sellest näitest, näete, kuidas kriitiliselt olulised sõltuvused mõjutada teenuse kättesaadavust. Isegi selleks postkasti andmebaasid mis mitte kunagi ebaõnnestub ( mitte saab kahjustada, ei saa kunagi mitte ühtegi viirusnakkused jne), saadavus jääb ikka alles alla 93,5%!
Järeldus: Suur hulk teenusesõltuvuste kättesaadavus väheneb.
Kõik, mida me teeme arvu vähendamine või sõltuvuste mõju avaldab positiivset mõju kindrali kohta teenuse kättesaadavus. Näiteks , saaksime parandada olukord lihtsustamise ja kindlustama serveri haldamine ja optimeerimine tööprotseduurid. Tehnilisest küljest, meie me võime proovida vähendage kogust teenusesõltuvused, tehes meie disaini lihtsam näiteks, kõrvaldades keerukad SAN-põhised salvestussüsteemid, kiudlülitid, massiivikontrollerid ja isegi RAID-kontrollerid ning asendades selle lihtsa DAS-iga minimaalselt liikuvad osad.
Teenuste sõltuvuste vähendamine iseenesest ei saa olla piisavalt tuua ligipääsetavus soovitud tasemele. Teine väga tõhus meetod
suurendada kättesaadavust ja minimeerida mõju kriitilised hooldussõltuvused on meelitada erinevaid meetodeid reservatsioonid nagu kasutamine kaks toiteallikat, NIC Teaming , serveri ühendus mitmele võrgu lülitid kasutades RAID-i operatsioonisüsteem, juurutades serverites riistvara tasakaalustajaid kliendi juurdepääs ja mitu koopiat postkasti andmebaasid. Aga kuidas täpselt toimub koondamise kasv võimaldab teil saavutada kõrge kättesaadavuse? Läheme üksikasjalikumalt kaaluma koormuse tasakaalustamine ja mitu andmebaasi koopiat sama oluline näiteid.
Kuidas broneeringud mõjutavad saadavust
Kontseptuaalselt tähendavad kõik koondamismeetodid sama asja: on olemas rohkem kui üks eksemplar komponent, mis on saadaval ja saab kasutada või samal ajal (nagu koormuse tasakaalustajad) või asendusena(nagu ka mitu andmebaasi koopiat). Oletame meil on n selle koopiad komponent (n serverit CAS-massiivis või n andmebaasi koopiad DAG-is). Isegi kui üks neist läheb korrast ära, teised ikka saab kasutada jaoks kindlustama kõrge tase ligipääsetavus. Ainuke olukord kui ilmneb tegelik teenusetõrge, kui kõik eksemplarid pole enam saadaval.
Nagu eelnevalt määratletud, ebaõnnestumise tõenäosus kellelegi see juhtum P \u003d 1 - A. Kõik eksemplarid statistiliselt sõltumatudüksteiselt, mis tähendab, et esitus või ebaõnnestumineükski neist ei mõjuta kättesaadavust muudel juhtudel. Näiteks selle ebaõnnestumine andmebaasi koopiad ei mõjuta ebaõnnestumise tõenäosus teise eksemplari jaoks see andmebaas(Loogiline nüanss on võimalik, kui kahjustatud koopia levitab muudatusi teistele juhtudele, kuid las ignoreeri seda tegur - lõpuks saate alati kasutada andmebaasi viivitatud koopiat või taastevalikut traditsiooniline varundamine).
Kasutades uuesti sama teoreemi tõenäosusteooria, ebaõnnestumise tõenäosus n sõltumatu komponendi komplekt on toode tõenäosused iga komponendi jaoks. Kuna kõik siin olevad komponendid on identsed (sama objekti erinevad eksemplarid):

On ilmne, kuidas P< 1, P n vähem P, mis tähendab, et ebaõnnestumise tõenäosus väheneb ja vastavalt suureneb saadavus:

Mõelge mõnele tõeline näide elust selguse huvides. Ütleme mida me paigaldame mitu koopiat postkasti andmebaasid; iga koopia asub ühel SATA-draivil. Statistiliselt on SATA-draivide rikkeprotsent aasta jooksul ~5%, mis annab meile 5%. ebaõnnestumise tõenäosus: P = 0,05 (tähendab 95% : A = 0,95). Kuidas muutub juurdepääsetavus? nagu lisate andmebaasi koopiad? Vaatame edasi järgmine tabel:
| Koopiate arv | Ebaõnnestumise tõenäosus | Kättesaadavuse tase |
| 1 | P 1 \u003d P \u003d 5% | A 1 = 1 - P 1 = 95% |
| 2 | P 2 \u003d P 2 = 0,25% | A 2 = 1 – P 2 = 99,75% |
| 3 | P 3 \u003d P 3 = 0,0125% | A 3 = 1 – P 3 = 99,9875% |
| 4 | P4 = P4 = 0,000625% | A 4 = 1 – P 4 = 99,9994% |
Muljetavaldav? Põhimõtteliselt iga lisakoopia siseneb SATA-draivi andmebaas korrutustegur 5% või 1/20, seega tõenäosus ebaõnnestumiste määr väheneb iga koopiaga 20 korda (ja vastavalt, kättesaadavus suureneb). Me näeme seda isegi kõige ebausaldusväärsem SATA-draivid, tutvustades ainult 4 andmebaasi koopiad toob meile andmebaasi kättesaadavus kell viis üheksa.
seda juba väga hea, aga kas saame hakkama veel parem? Kas me saame suurendada juurdepääsetavust siiski tegemata arhitektuurilised muutused(näiteks kui lisate teise andmebaasi koopiad)?
Tegelikult me saame. Kui me parandame individuaalset juurdepääsetavust mis tahes komponent sõltuvus, see jääbki võimendaja üldine juurdepääsetavus teenindus ja toob palju kaasa tugevam mõju kui lisamisest üleliigne komponent. Näiteks üks võimalikest viise, kuidas seda teha, on kasutus SATA-draivide asemel peaaegu SAS-draivid. Ligikaudu SAS-draivide aastane rikete määr on ~2,75%, mitte ~5% SATA puhul. See vähendab ebaõnnestumise tõenäosus salvestuskomponendi jaoks ja seega suurendada üldist teenuse kättesaadavus. Piisab, kui võrrelda mõju alates mitme lisamine andmebaasi koopiad:
5% AFR suhe = 1/20 = iga uue eksemplari korrutamine teeb kahju andmebaasid on 20 korda haruldasemad.
2,75% AFR = 1/36 korrutustegur= iga uus eksemplar teeb kahju andmebaasid on 36 korda haruldasemad.
seda olulist mõjuandmebaasi kättesaadavus selgitab ka Exchange'i loomuliku andmekaitse kontseptsiooni kasutamise juhiseid, mis selgitab, et andmebaasist saab teha mitu koopiat. traditsioonilise asendamine varukoopiad, kui need on kasutusele võetud piisav(kolm või enam).
Sama loogika kehtib juurde mitme kasutuselevõtt kliendi juurdepääsu serverid CAS-massiivis mitu võrgu lülitid jne. Oletame, et meie kasutusele 4 koopiat andmebaasist ja 4 kliendi juurdepääsu server ja läheme tagasi varem analüüsitud saadavuse tabeli komponendi juurde:
| Kriitiline sõltuvus | Ebaõnnestumise tõenäosus | Kättesaadavuse tase |
| Postkasti server ja salvestusruum (4 koopiat) | 5% ^ 4 = 0.000625% | 99.999375% |
| Client Access Server (4 serverit juurutatakse eraldi) | 1% ^ 4 = 0.000001% | 99.999999% |
| Net | 0.5% | 99.5% |
| Toit | 0.1% | 99.9% |
| Koguväärtus (sõltub kõigist määratud komponentidest) | 0.6% | 99.399878% |
Meie näete, kuidas me just kasutasime 4 kliendi juurdepääsu server ja 4 andmebaasi koopiad, ebaõnnestumise tõenäosusüldteenustest vähenes enam kui 10 korda (6,5%-lt 0,6%-le) ja vastavalt teenuse kättesaadavus tõusis 93,5%-lt palju auväärsemale 99,4%-le!
Järeldus: liiasuse lisamine sõltuvustele suurendab ligipääsetavust.
Ühendame koos
Huvitav küsimus varasematest leidudest. Meie analüüsitud kaks erinevat mõjutav tegur kindrali jaoks teenuse kättesaadavus kaks erinevatel viisidel
ja leidis kaks selget järeldust:
lisamine süsteemsem sõltuvused vähendavad kättesaadavust
liiasuse lisamine süsteemisõltuvustesse suurendab kättesaadavust
Mis juhtub, kui kombineerida mõlemad tegurid lahenduseks? Millised tendentsid on tugevamad?
Kaaluge järgmist stsenaariumi:
DAG-is kasutame kahte postkastiserverit kahe koopiaga postkasti andmebaasid(üks eksemplar igas serveris) ja me kasutame kahte serverit kliendi juurdepääs massiivides koos koormuse tasakaalustamisega. (Lihtsuse huvides teeme seda ainult arvestama Kättesaadavus postkasti andmebaasid jaoks kliendiühendused rolli arvestamata Hub Transpordi server ja UM)
. Kui eeldame, et iga serveril on oma individuaalne ebaõnnestumise tõenäosus P , kas selline süsteem oleks parem või halvem kui ühe juurutatud eraldiseisva Exchange'i serveri kasutamine nii postkastiserveri rollidega kui ka kliendi juurdepääs?

Esimese stsenaariumi korral, postkasti serverid on iseseisvad ja muutub kättesaamatuks ainult siis, kui mõlemad serverid ebaõnnestuvad. Ebaõnnestumise tõenäosus komplekt kahest postkasti serverid saab P× P = P 2. Sellest lähtuvalt on selle kättesaadavus AMBX = 1 – P2. Sama loogikat järgides CAS-teenus ei ole saadaval ainult siis, kui mõlemad serverid kliendi juurdepääs ebaõnnestub, seega tõenäosus ebaõnnestumine kahe komplekti jaoks kliendi juurdepääsu serverid saab jälle olema P× P = P 2
ja vastavalt selle kättesaadavus CAS = 1 – P2.
Sel juhul, nagu me juba aru saime, kaks postkastiserverit või kaks serverit kliendi juurdepääs on näitedüleliigne süsteemi komponendid.
Jätkame seda stsenaariumi. Selleks, et kogu süsteem oleks saadaval, tuleb mõlemad serverite komplektid (postkasti serverite komplekt ja kliendi juurdepääsu serverid) peaks olema saadavalüheaegselt. Mitte ebaõnnestuda samal ajal kuid samal ajal saadaval sest nüüd nad esindavad süsteemne sõltuvused, kuid mitte üleliigsed komponendid. See tähendab, et üldiselt teenuse kättesaadavus on toodeligipääsetavusiga komplekt:
Muidugi, teine variant palju lihtsam, sest see on olemas ainult üks server ja kaaluma selle kättesaadavuslihtsalt A = 1 – P.
Nii nüüd meie arvutatud väärtused ligipääsetavus mõlema stsenaariumi jaoks. W mille tähendus eespool, (1-P 2
) 2
või 1-P?
Kui ehitada diagrammid mõlemad funktsioonid, Me näeme järgnev käitumine:

Näeme, et väikese P väärtuse korral on kohalolek integreeritud süsteem 4-st serverist on suurem kui ühe serveri olemasolul. Pole midagi üllatavat, see on see, mida me ootasime, eks? Kuid P ~ 0,618 juures ristuvad kaks lõiku ja punktis suured väärtused P üks süsteem serveril on tegelikult suurem kättesaadavus. Muidugi oleks tõenäolisem eeldada, et P väärtus peaks olema väga lähedal nullile päris elu. Kui aga plaanime ehitada oma lahenduse väga ebausaldusväärsete komponentidega, on ühe serveri lahendus ilmselt parem.
Rikkepunktide mõju
Kahjuks on ülalkirjeldatud kasutuselevõtu stsenaariumid reaalses elus haruldased. Näiteks milline oleks saadavuse muutumise mõju mitme rolliga serveri juurutamisel? Märkasime, et ülaltoodud näites vähendab serverirollide kombinatsioon tõhusalt teenuse sõltuvuste arvu, nii et ilmselt on kõik korras? Mis juhtub, kui hostime kaks andmebaasi koopiat samast andmebaasist samas SAN- või DAS-massiivis? Mis siis, kui kõik postkasti serverid on ühendatud sama võrgulülitiga? Mis siis, kui meil on kõik ülaltoodud ja rohkemgi veel?
Kõik need olukorrad panevad meid silmitsi ebaõnnestumise punkti kontseptsiooniga. Ülaltoodud serveri riistvaranäidetes tähistavad SAN-massiivi või võrgulüliti tõrkepunkte. Rikkepunkt katkestab kombineeritud komponentide sõltumatuse või liiasuse – näiteks serveri riistvarakomponentide rike koos rollide kombinatsiooniga tähendab, et kõik selle serveri rollid muutuvad kättesaamatuks; vastavalt tähendab ketta või SAN-massiivi rike, et kõik sellel kettal või massiivil asuvate andmebaaside koopiad muutuvad kättesaamatuks.
Kuid ebaõnnestumise punkti olemasolu ei pruugi olla halb. Oluline erinevus seisneb selles, et tõrkepunkti moodustavad komponendid erinevad süsteemisõltuvustest või üleliigsetest süsteemikomponentidest. Selle erinevuse mõistmiseks vaatame kahte ülaltoodud näidet.
Mitme rolliga serveriskript
Võrdleme kahe erineva süsteemi olemasolu:
1. Postkastiserveri ja Client Accessi serveri rollid majutatud samas serveris, mille riistvaratõrke tõenäosus on P;
2. Samad rollid on majutatud kahes eraldi serveris, millest igaühel on sama riistvaratõrke tõenäosus.
Esimesel juhul kujutab ühe serveri riistvara endast tõrkepunkti. See tähendab, et kõik hostitud rollid on saadaval või mitte. See on lihtne, üldiselt on sellise süsteemi kättesaadavus A = 1 - P.
Teisel juhul on teenus üldiselt saadaval ainult siis, kui mõlemad serverid on eraldi saadaval (kuna iga roll on kriitiline sõltuvus). Seetõttu on tõenäosusteooria põhjal selle olemasolu A × A = A2.
Jällegi, nagu a<1, это означает, что A2 < А, так во втором случае доступность будет ниже.
Näib, et saame lisada muid Exchange'i serveri rolle (vajadusel Hub Transport ja Unified Messaging) samamoodi ilma seda loogikat rikkumata.
Järeldus: Exchange'i serverirollide hostimine mitme rolliga serveris parandab üldist teenuse kättesaadavust.
Jagatud salvestusruumi stsenaarium
Vaatame nüüd teist tõrkepunkti stsenaariumi (kaks Exchange'i andmebaasi koopiat samas massiivis) ja võrdleme andmebaasi saadavust kahel järgmisel juhul:
1. Kaks andmebaasi koopiat, mis on majutatud samal salvestusruumil (SAN- või DAS-massiivil), mille rikke tõenäosus on P;
2. Kahes eraldi salvestussüsteemis hostitud andmebaaside samad koopiad, millest igaühel on sama rikke tõenäosus.
Esimesel juhul kujutab jagatud salvestuskoht tõrkekohta. Nagu eelmises stsenaariumis, tähendab see seda, et mõlemad andmebaasi koopiad on saadaval või ei ole korraga saadaval, seega on üldine saadavuse tase jälle A = 1 - P.
Teisel juhul on teenus üldiselt saadaval, kui vähemalt üks süsteem on saadaval, ja pole saadaval ainult siis, kui mõlemad süsteemid ebaõnnestuvad. Salvestussüsteemid on sõltumatud. Seetõttu on kogu teenuse rikke tõenäosus P × P = P2 ja vastavalt sellele on teenuse üldine kättesaadavus A = 1 – P2.
Jällegi, kui P< 1, то это означает, что Р2 <Р, и, следовательно, 1 – P2 >1 - P. See tähendab, et teisel juhul on kättesaadavuse tase palju kõrgem.
Järeldus: sama andmebaasi koopiate paigutamine samasse salvestussüsteemi vähendab üldist teenuse kättesaadavust.
Mis vahe on neil kahel stsenaariumil, miks tõrkepunktide sisseviimine suurendab esimesel juhul saadavust ja vähendab teisel juhul?
Selle põhjuseks on asjaolu, et esimesel juhul ühendab tõrkepunkt sõltuvuste säilitamise, vähendades tõhusalt nende arvu ja suurendades seega saadavust, samal ajal kui teisel juhul ühendab tõrkepunkt üleliigseid komponente, vähendades tõhusalt koondamist ja seetõttu halveneb saadavus.
Kõik need mõisted ja järeldused võib esitada järgmisel kujul:

järeldused
Exchange 2010 arhitektuur annab võimsa võimeid lisamise eest koondamine (näiteks, mitme kasutuselevõtt andmebaasi koopiad või mitu Client Access serverit massiivides CAS) ja vähendada arv süsteemseid sõltuvused ( kombineerides Exchange'i serveri rollid või kasutades lihtne salvestusarhitektuurid ilma liigne kogus kriitilised komponendid). Lihtsad reeglid ja valemid aastal esitatud see artikkel lubama arvutama mõju kuludele ligipääsetavus kasutuselevõtust lisaks andmebaasi koopiad või kombinatsioonist Exchange'i serveri rollid. T samuti võimalik arvutama mõju ebaõnnestumise punktid. Päris elu harva mahub sisse lihtne põhiline stsenaariumid, ja vajapalju keerulisem arvutused, Et saada mõistlik hinnangud ligipääsetavus tõelised süsteemid; seda saab teha lihtsamaks jalihtne mõõta kättesaadavuse tase statistiliselt ja kontrollida, kas see vastab nõuetele SLA. Sellest hoolimata, tegurite mõistmine ligipääsetavust mõjutav koos Koos keerukus tehniline lahendus peaks aitama disain lahendus õige ja jõuda märkimisväärne tõus üldine ligipääsetavus teenuseid isegi kõige nõudlikumate ärinõuete jaoks.
Ülalkirjeldatud mõõdikuid saab kasutada klientidega teenuse kättesaadavuse lepingute sõlmimisel. Need lepingud on osa teenusetaseme lepingutest. Järgmine valem aitab kindlaks teha, kas saavutatud saadavuse tase vastab kokkulepitud nõuetele:
Riis. 14.6. Kättesaadavusvalem (Allikas: OGC)
Saavutatud süsteemi tööaeg võrdub kokkulepitud tööaja ja tekkinud seisaku vahega. Näiteks: kui lepiti kokku teenuse 98% kättesaadavuse osas tööpäeviti kella 7.00-19.00 ja sel perioodil toimus teenuse kahetunnine rike, siis saavutatud tööaeg (kättesaadavuse protsent) võrdub:
(5x12-2)/(5 X 12) X 100% = 96,7%
Süsteemi seisakuanalüüs (SOA)
Seda meetodit saab kasutada rikete põhjuste väljaselgitamiseks, IT-organisatsiooni ja selle protsesside efektiivsuse uurimiseks ning teenuse täiustamise ettepanekute esitamiseks ja elluviimiseks.
SOA meetodi omadused:
Lai ulatus: see ei piirdu infrastruktuuriga, vaid hõlmab ka protsesse, protseduure ja ettevõtte kultuuri aspekte;
Küsimuste läbimõtlemine kliendi seisukohast;
Meetodi ühine rakendamine kliendi ja IT organisatsiooni esindajate poolt (SOA meetodi meeskond).
Selle meetodi eelised hõlmavad lähenemise tõhusust, otsesuhtlust kliendi ja tarnija vahel ning laiemat võimalust teha ettepanekuid teenuse parandamiseks.
Tehnilise järelevalve ametikoht (TOR)
See meetod seisneb selles, et spetsiaalne IT-meeskond jälgib ühte valitud saadavuse aspekti. Seda saab kasutada juhtudel, kui tavapärased vahendid ei paku piisavat tuge. TOP-meetod võimaldab ühendada disainerite ja süsteemihaldurite teadmised.
Teenuse saadavuse arvutused
Selle meetodi peamine eelis on ratsionaalne, tõhus ja mitteametlik lähenemine, mis annab kiiresti tulemusi.
itil protsesside automatiseerimise tarkvara
- bmc tarkvara
- arvutikaaslased
- Hewlett Packard
- Microsoft
bmc tarkvara
BMC Software on maailmas tuntud võrgu-, rakendus-, andmebaasi-, ERP- ja CRM-i haldustööriistade arendaja ja pakkuja, mis parandab kriitiliste ärirakenduste ja andmete kättesaadavust, jõudlust ja taastatavust. BMC-tooted on saadaval paljudele platvormidele, sealhulgas UNIX-i, Windowsi, OS/2, OS/390, OpenVMS-i ja NetWare'i erinevate rakenduste ja versioonide jaoks. BMC toodetele iseloomulikest omadustest tuleb esmajoones esile tõsta keskendumist kasutajate teenusetaseme lepingute (Service Level Agreement, SLA) toetamisele ja sellise lepingu rakendamisele suunatud toimiva mudeli ülesehitamisele ning nende kõrgele jõudlusele ( joonis 1). Ettevõte pakub IT infrastruktuuri haldamiseks järgmisi tooteperekondi:
- BMC rakenduste haldus- tööriist on mõeldud ärirakenduste (sh Oracle'i ja SAP-i rakendused) ja serveritoodete (nt Microsoft Exchange ja J2EE serverid BEA WebLogic, IBM WebSphere jne) jõudluse ja saadavuse haldamiseks;
- BMC andmebaasihaldus- tööriist DBMS juhtivate tootjate - Oracle, IBM, Microsoft, Sybase hallatavate andmebaaside administreerimiseks, jõudluse haldamiseks ja taastamiseks;
- BMC infrastruktuuri juhtimine- tööriist serverite ja suurarvutite operatsioonisüsteemide, andmesalvestuse, võrkude, riistvara, vahevara haldamiseks ning nende tarkvarakategooriate jõudluse optimeerimiseks;
- BMC operatsioonide juhtimine- tööriist rutiinsete toimingute tegemiseks ajakava alusel ja võrgustikus toimuvatest sündmustest aruandluseks;
- BMC Remedy Service Management- tööriist rakenduste rikete otsimiseks, tuvastamiseks, modelleerimiseks ja neile reageerimiseks;
- BMC turvahaldus- tööriist kasutajate juurdepääsuõiguste haldamiseks rakendustele ja ettevõtte ressurssidele.
BMC rakenduste andmeid saab salvestada Atrium CMDB (Configuration Management Database) BMC konfiguratsiooni andmebaasis, kus on mugavad andmete visualiseerimise tööriistad.
bmc tarkvara
Pange tähele, et BMC tooted sisaldavad dokumenteeritud rakenduste programmeerimisliidest, mis võimaldab luua nende põhjal oma lahendusi ja integreerida BMC tööriistu teiste rakendustega.

Riis. 1. BMC toodetega hõlmatud IT infrastruktuuri haldamise valdkonnad
arvutikaaslased
Computer Associates'i (CA) IT-infrastruktuuri haldustoodete perekonda Unicenter saab kohandada nii, et need sobiksid praktiliselt iga arvutikeskkonnaga.
Sellesse perekonda kuuluvad järgmised tooted:
- Unicenter Asset Management- tööriist ettevõtte IT-varade haldamise automatiseerimiseks, mille abil viiakse läbi IT-ressursside terviklik arvestus ja kontroll. Unicenter Asset Management süsteemi funktsionaalsus aitab parandada ettevõtte IT varadega seotud juhtimisotsuste kvaliteeti ja vähendada sellega kaasnevaid riske. Unicenter Asset Management jälgib rakenduste kasutamist serverites, personaalarvutites ja muudes klientseadmetes. Lisaks võimaldab see toode automatiseerida IT varahaldusprotsesse, sealhulgas ettevõtte võrgus töötava tarkvara ja riistvara raamatupidamist ja inventuuri, IT infrastruktuuri erinevate komponentide hooldust, litsentside administreerimist ja aruandlust heterogeensetes keskkondades (joonis 2);

Riis. 2. Computer Associatesi toodetega hõlmatud IT-infrastruktuuri integreeritud halduse valdkonnad
- Unicenter tarkvara tarnimine- pakub tarkvara juurutamise ja värskendamise protsesside automatiseerimist laua-, mobiil- ja pihuarvutites, samuti serverites heterogeensetes võrgukeskkondades, sealhulgas rakenduste tarnimine, paikade ja värskenduste levitamine, süsteemi konfiguratsiooni haldamine ja installide tagasipööramine erinevatel tarkvara- ja riistvaraplatvormidel . See toode loob tingimused IT-teenuste efektiivsuse tõstmiseks ja ettevõtluse infotoe kulude vähendamiseks IT protsesside automatiseerimise ja täiustatud iseteenindusvõimalustega rakenduskataloogide juurutamise kaudu. Üks Unicenter Software Delivery peamisi eeliseid on tarkvara installi- ja hooldusprotsesside kõrge automatiseerituse tase ning rakenduste tarnimise lubade paindlik ja üksikasjalik kontroll;
- Unicenter kaugjuhtimispult on usaldusväärne ja turvaline ettevõtte süsteem Windowsi arvutite kaugjuhtimiseks. Kaughaldusülesannete loend sisaldab kaugteenuste, nagu võrgurakendused, serverihaldus ja lõppkasutaja arvutite kaugjuhtimine (näiteks tehnilise toe pakkumisel). See süsteem on üks parimaid tööstuslahendusi oma klassis ja pakub tsentraliseeritud süsteemihooldust, poliitikapõhist haldust, juurdepääsukontrolli, seansside auditeerimist ja täiustatud haldusvõimalusi. Unicenter Remote Control vastab täielikult suurettevõtete kaugjuhtimisnõuetele ja võimaldab operaatoril täita korraga mitut ülesannet: kopeerida faile kaugarvutisse, suhelda kasutajaga, käivitada rakendusi, jälgida ja jäädvustada kasutaja toiminguid ning hallata. konfiguratsiooni- ja turvaseaded. Tuleb märkida, et Unicenter Remote Controli arendamise käigus pöörati erilist tähelepanu süsteemi juurutamise ja arendamise aja lühendamisele.
Hewlett Packard
HP OpenView on tarkvaratoodete komplekt, mis on keskendunud igas suuruses ettevõtte infotehnoloogia haldamisele – alates väikestest Windowsi-põhistest serverisüsteemidest kuni UNIX-i, Linuxi ja Windowsi erinevatel versioonidel põhinevate suurte hajutatud süsteemideni, mis sisaldavad mitut tuhat arvutit. See kompleks sisaldab tööriistu võrkude, operatsioonisüsteemide, rakenduste, aga ka nende jõudluse haldamiseks, andmete, teenuste kopeerimiseks ja salvestamiseks.
HP OpenView tarkvaralahenduste portfell koosneb mitmest tooteperekonnast (joonis 3), sealhulgas serverite ja rakenduste haldamine, salvestusruum, võrgundus, Interneti-tehnoloogiad ja telekommunikatsiooniseadmed (seal on hulk HP OpenView tooteid, mis on loodud spetsiaalselt telekommunikatsiooniettevõtetele ja tänapäeval HP on tuntuim telekommunikatsiooniseadmete juhtseadmete tarnija). Eraldi märgime ära IT-teenuste haldustööriistade olemasolu HP lahenduste portfellis.

Riis. 3. Tarkvaralahenduste portfell HP OpenView IT-osakondadele
Serverite ja rakenduste haldamise tööriistad tuleks eelkõige omistada HP OpenView operatsioonid Windowsile ja HP OpenView operatsioonid Unixi jaoks. Need tooted on loodud rakenduste jõudluse jälgimiseks ja haldamiseks ning võrgu- ja rakendussündmuste juhtimiseks. HP OpenView Operations for Windows integreerub võrgu infrastruktuuri haldustööriistadega HP OpenView võrgusõlmede haldur, mis võimaldab teil automaatselt otsida võrku lisatud uusi servereid ning seejärel teenuseotsingu tulemuste põhjal automaatselt juurutada vajalikud komponendid ja poliitikad.
Hewlett Packard
Rakenduse jõudluse haldamiseks sisaldab see perekond tööriistu HP OpenView Performance Manager ja Esinemisagendid, mis võimaldavad ühe liidese abil tsentraalselt jälgida, analüüsida ja ennustada ressursside kasutamist hajutatud ja heterogeensetes keskkondades, samuti HP Open View Performance Insight, mis aitab jälgida sündmusi võrgus ja rakendustes, neid analüüsida. Lahendused HP OpenVew aruandepaketid ja HP Open View Reporter mõeldud HP OpenView rakendustest saadud andmete põhjal aruannete loomiseks ettevõtte hajutatud IT-infrastruktuuri toimimise kohta.
Identiteedi ja IT-ressurssidele juurdepääsu haldamiseks sisaldab HP OpenView perekond tooteid HP OpenView Select Identity, HP OpenView Select Access ja HP OpenView Select Federation ning serveri DBMS-i andmete varundamise ja taastamise haldamiseks - HP OpenView Storage Data Protector. Viimane neist toodetest on ettevõtte tasemel andmekaitse- ja avariitaastelahendus, mis rakendab kohese taastamise tehnoloogiat, aga ka avariitaaste alternatiive planeerimata seisakute kõrvaldamiseks, mis võimaldab mõne minutiga taastada infosüsteemi tervise.
Märkame ka tooteperekonna olemasolu, mis on mõeldud lõppkasutajatega suhtlemiseks, et parandada nende teenuse kvaliteeti, - HP OpenView teeninduslaud, samuti äriprotsesside jälgimise tööriistad HP OpenView äriprotsesside ülevaade ja haldustööriistad teenustele orienteeritud arhitektuuri jaoks - HP OpenView teenusele orienteeritud arhitektuurihaldur.
Hewlett Packard
Interneti-teenuste haldamiseks pakub see tootepere lahenduse HP OpenView Interneti-teenused, mis võimaldab rakendusteenuste, Interneti-teenuste ja protokollide välist kontrollimist, modelleerides kasutajate päringuid kataloogidele, meiliteenustele, veebiteenustele, kaugjuurdepääsuteenustele (sh sissehelistamis- ja traadita juurdepääs).
IBM Tivoli tootepere, mis on mõeldud rakenduste haldamiseks erineva suurusega ettevõtetes, põhineb põhikomponentide komplektil, millest luuakse ettevõttespetsiifiline lahendus. Selle tootepere peamiseks eristavaks tunnuseks on IT-taristu nn proaktiivne juhtimine, mis suudab tuvastada ja kõrvaldada rikkeid juba enne nende tekkimist. Tivoli perekonna tooted on saadaval AIX, HP-UX, Sun Solaris, Windows, Novell NetWare, OS/2, AS/400, Linux, z/OS, OS/390 platvormidele. Pange tähele, et hiljuti soovitab IBM juurutada Tivoli perekonna tooteid, et järgida ITIL-i (Information Technology Infrastructure Library) teegi meetodeid, nihutades oma toodete positsioneerimisel fookuse IT-ressursside ja süsteemide halduselt IT-teenuste haldamisele (joonis 4).

Riis. 4. Mõned Tivoli tarkvaratooted, mis toetavad ITIL-i teenusehaldusprotsessi
Tivoli tooteperekond sisaldab konfiguratsioonihaldus- ja töötugilahendusi järgmiste jaoks:
- IBM Tivoli Configuration Manager- võimaldab hallata tarkvara installimist ja värskendamist, sealhulgas pihuarvutites;
- IBM Tivoli litsentsihaldur- mõeldud tarkvara inventuuri jaoks;
- IBM Tivoli kaugjuhtimispult- võimaldab määrata poliitikaid ettevõtte IT-ressursside haldamiseks ja töölauasüsteemide kaughaldamiseks;
- IBM Tivoli töökoormuse ajakava- võimaldab töökoormust automatiseerida.
Lisaks konfiguratsioonihaldustööriistadele sisaldab Tivoli tootepere jõudluse ja saadavuse halduslahendusi:
- IBM Tivoli jälgimine- rakendada erinevate süsteemide hajutatud monitooringut, automaatset probleemide tuvastamist ja kõrvaldamist ning trendianalüüsi;
- IBM Tivoli Monitoring for Databases(IBM, Oracle ja Microsoft toodetud DBMS-id on toetatud) ja Sybase'i Tivoli Manager- serverite ja andmebaaside tsentraliseeritud haldamiseks;
- IBM Tivoli Monitoring for Web Infrastructure- hallata veebiservereid ja rakendusservereid;
- IBM Tivoli Monitoring for Applications- SAP ärirakenduste haldamiseks;
- IBM Tivoli Analyzer Lotus Domino 6.0 jaoks ja IBM Tivoli jälgimine tehingute toimivuse jaoks- tuvastada IBMi enda serveritoodetel põhinevate süsteemide jõudlusprobleeme;
- IBM Tivoli veebisaidi analüsaator- analüüsida külastajate külastatavust, lehe külastatavuse statistikat, veebilehe sisu terviklikkust;
- IBM Tivoli teenusetaseme nõustaja- pakkuda kvantitatiivse jõudlusanalüüsi kaudu ennustavat kontrolli ja rikete prognoosimist;
- IBM Tivoli NetView- võrgu haldamiseks;
- IBM Tivoli Switch Analyzer- kõigi võrgukihi lülitite avastamine ja asustus;
- IBM Tivoli Enterprise Console- mitmetasandiliseks tõrkeotsinguks ja sündmuste analüüsiks.
Lisaks on IT-ressursside jaotamise ja tippkoormuse automatiseeritud haldamiseks mitmeid lahendusi.
Tivoli perekonda kuuluvad ka turvatooted:
- IBMDirectory Server- turvaandmete sünkroonimiseks kõigis kasutatavates rakendustes;
- IBM Directory Integrator- integreerida kataloogides, andmebaasides, koostöösüsteemides ja ärirakendustes sisalduvaid identifitseerimisparameetreid;
- IBM Tivoli Identity Manager ja IBM Tivoli Access Manager operatsioonisüsteemidele- rakendustele ja operatsioonisüsteemidele juurdepääsu kontrollimiseks;
- IBM Tivoli riskihaldur- võrgukaitse tsentraliseeritud haldamiseks.
Lisaks sisaldab Tivoli perekond laias valikus varundus- ja salvestushaldustooteid.
Microsoft
Kuigi täna ei ole Microsoft IT infrastruktuuri haldustööriistade turuliider, on ettevõtte rakenduste haldustööriistad meie riigis laialdaselt kasutusel.
Microsoft Systems Management Serveri (SMS) ja Microsoft Operations Manageri (MOM) tööriistade ning Microsofti serverite operatsioonisüsteemide uusimate versioonide kasutajatele saadaolevate haldustööriistade põhieesmärk (nt automatiseeritud juurutusteenused, kauginstalliteenused, Microsoft Group Policy Management Console, Microsoft Windows Update Services), - tarkvarahaldus, Microsofti operatsioonisüsteemide ja nende jaoks loodud rakenduste automaatne installimine, uuenduste automaatne kohaletoimetamine, juurdepääsukontroll ja kasutajaõigused (joon. 5).

Riis. 5. Infosüsteemide haldamine Microsoft Operations Manageri ja Microsoft Systems Management Serveri abil
Microsoft Systems Management Server on mõeldud tarkvara automaatse levitamise ja arvestuse tagamiseks suurtes hajussüsteemides, mis põhinevad Microsofti enda operatsioonisüsteemidel, sealhulgas planeerimine koos riist- ja tarkvara määramisega kohtvõrgus, verifitseerimine, analüüs, ärirakenduste juurutamine erinevatele sihtkasutajarühmadele , rakenduste installimine uutele töökohtadele vastavalt kasutajaõigustele. See toode võimaldab sihipäraselt installida erinevat tarkvara erinevatele kasutajarühmadele, samuti lahendada tarkvara inventuuriga seotud probleeme ning kontrollida tarkvara ja riistvararessursside kasutamist, kogudes teavet võrku installitud tarkvaratoodete ja seadmete ning nende kasutamise kohta.
Microsoft
Microsofti operatsioonide haldur on loodud võrgu-, riistvara- ja rakendusprobleemide tuvastamiseks ja tõrkeotsinguks, jälgides vahetult käimasolevaid sündmusi, samuti võrguressursside olekut ja jõudlust ning väljastades hoiatusi võimalike probleemide kohta (joonis 6).

Riis. 6. Serverite oleku jälgimine Microsoft Operations Manageri abil
Toode on mõeldud väikeettevõtete või spetsialiseeritud serverirühmade (kuni 10 tk) IT-infrastruktuuri haldamiseks. Microsoft Operations Manager 2005 Workgroup Edition. See võimaldab teil tuvastada võimalikud ohud tarkvara töös ja sisseehitatud analüüsitööriistade abil vältida nende eskaleerumist tõsisteks probleemideks, parandada IT-toimingute tõhusust, lihtsustada heterogeensete platvormide ja rakenduste tuge ning luua oma hoolduspakette. .
Lisaks on Microsofti serveritoodetel põhinevatele IT-taristu komponentidele eraldi jõudlushalduse ja sündmuste analüüsi lahendused, nt Active Directory halduspakett- Active Directory kataloogiteenuse oleku jälgimiseks, Exchange'i halduspakett- hallata sõnumsideteenuseid ja Exchange'i andmesalve, aga ka mitmeid muid tooteid. Koostalitlusvõime tagamiseks kolmandate osapoolte IT-infrastruktuuri haldustööriistadega on saadaval toode MOM Connector Framework, mis võimaldab hoiatuste kahesuunalist levitamist ja andmete sünkroonimist veebiteenuste abil.
IB juhtimine
- Cobit - "info- ja seotud tehnoloogiate kontrolli eesmärgid"
- Lugege 1. jaotist
- Lugege 1. jaotist
- Lugege 1. jaotist
- Lugege 1. jaotist
Info- ja seotud tehnoloogiate kontrollieesmärkide (CobiT) standard, mis on nüüd kolmandas väljaandes, aitab lahendada mitmeid kontrollivajadusi, ühendades äririski, kontrollinõuded ja tehnilised probleemid. See võimaldab standardi raames kujundada hea IT-juhtimise tava kõigis protsessirühmades, samuti kirjeldada IT tegevuste liike hallatava ja loogiliselt üles ehitatud struktuuri näol. CobiTi "hea tava" on ekspertide konsensussoovituste kogum, mis aitab optimeerida IT-investeeringuid ja annab mõõdiku, mida hädaolukorras juhtida.
CobiT põhikontseptsioon seisneb selles, et IT-juhtimine käsitleb teavet tootena, mis on vajalik ärieesmärkide või -nõuete toetamiseks ning IT ja sellega seotud ressursside kombineeritud kasutamise tulemusena, mida IT protsessid hallavad.
CobiT standard sisaldab järgmisi raamatute seeriaid:
1. Juhiseks kokkuvõte.
2. Põhitõed.
3. Kontrollväravad (üksikasjalikud väravad - 318 tükki)
4. Juhtimisjuhend.
5. Auditi juhised.
6. Rakendusmeetodid.

CobiT standard identifitseerib 34 IT-protsessi, mis on rühmitatud järgmisse nelja rühma (joonis 1.1):
1. Planeerimine ja korraldamine – protsessid, mis hõlmavad strateegiat ja taktikat, samuti viiside kindlaksmääramist, kuidas IT-arendus aitab kõige paremini kaasa ärieesmärkide saavutamisele.
2. Omandamine ja juurutamine - protsessid, mis hõlmavad IT-lahenduste väljatöötamist ja omandamist, mis tuleb integreerida äriprotsessi. Olemasolevate süsteemide muutmine.
Cobit - "info- ja seotud tehnoloogiate kontrolli eesmärgid"
3. Kasutamine ja hooldus – protsessid, mis tegelikult pakuvad vajalikke teenuseid.
4. Kontroll – juhtimisjärelevalve ja sõltumatu hindamise protsessid, mis hõlmavad sise- ja välisauditit või muid allikaid.
Iga 34 IT-protsessi jaoks on määratletud üks IT protsessitaseme kontrollieesmärk (eesmärk või soovitud tulemus, mis saavutatakse kontrolliprotseduuride rakendamisega IT tegevustes). Need kontrollieesmärgid on jaotatud üksikasjalikeks kontrollieesmärkideks. CobiT standardis on 318 sellist üksikasjalikku sihtmärki.

Joonis 1.1. IT töötleb CobiT-i
CobiT järgi kasutatakse IT-protsesse järgmiste 7 teabenõude täitmiseks (osaliselt kattuvad).
1. Kasulikkus – teave on asjakohane ja kooskõlas BP-ga, edastatud õigeaegselt, järjepidev ja kasutatav.
2. Tõhusus - ressursside optimaalsel kasutamisel põhineva teabe edastamine.
3. Konfidentsiaalsus – teabe kaitse volitamata juurdepääsu eest.
4. Terviklikkus – teabe täpsus ja täielikkus vastavalt äriväärtustele ja ootustele.
5. Kättesaadavus – teave on BP nõudmisel saadaval praegu ja edaspidi.
6. Vastavus - vastavus BP-le kehtivate õigusaktide, reguleerivate organite ja lepinguliste kohustuste nõuetele.
7. Ausus – juhtkonnale vajaliku teabe andmine organisatsiooni finantstegevusega seotud kohustuste juhtimiseks ja täitmiseks ning aruandlus regulaatoritele.
Cobit - "info- ja seotud tehnoloogiate kontrolli eesmärgid"
IT protsesside juhtimise eesmärgid võivad vastata ülaltoodud teabenõuetele ja olla esmased või sekundaarsed.
CobiT määratleb ka ülaltoodud teabenõuete täitmisega seotud IT-ressursid. IT-ressursse on 5 klassi:
1. Andmed - infoobjektid laiemas tähenduses, sh struktureerimata, graafika, heli.
2. Rakendused – manuaalsete ja tarkvaraliste protseduuride komplekt.
3. Tehnoloogia – riistvara, OS, DBMS, võrgud, multimeedia jne.
4. Infrastruktuur – kõik ressursid IP hostimiseks ja toetamiseks.
5. Personal – hõlmab personali ja nende oskusi, teadlikkust ja oskust planeerida, organiseerida, omandada, tarnida, hooldada ja kontrollida IS-i ja teenuseid.
IT protsesside juhtimise eesmärgid, nende seos infole ja IT ressurssidele esitatavate nõuetega on toodud joonisel 1.2.

Joonis 1.2. IT protsesside juhtimise eesmärgid
Seega on iga kontrollieesmärgi jaoks määratletud peamised ja teisese teabe nõuded, mida need toetavad. Samuti määratakse kindlaks, millised ressursid on nende nõuete täitmiseks kaasatud.
CobiT raamat "Juhtimisjuhend" tutvustab organisatsiooni protsesside arengutaseme mudelit koos arengutaseme hinnanguga 0-st (olematu) kuni 5-ni (optimeeritud). Seda küpsusmudelit kasutatakse edaspidi IT-protsesside auditite läbiviimisel ja küsimusele vastamisel – kuivõrd IT protsessid vastavad vajalikele nõuetele. Sellest vaatenurgast on CobiT-l head kokkupuutepunktid Venemaa pangandusstandardiga.
CobiT-is sisestatakse KPI-d iga 34 protsessi jaoks. Nad määratlevad võrdlusalused, mis annavad juhtkonnale tagantjärele märku, et IT-protsess vastab ärinõuetele. Neid võrdlusaluseid väljendatakse tavaliselt teabenõuetena, näiteks:
Cobit - "info- ja seotud tehnoloogiate kontrolli eesmärgid"
Ärivajaduste rahuldamiseks vajaliku teabe kättesaadavus.
Puuduvad terviklikkuse ega konfidentsiaalsusega seotud riskid.
Protsesside ja toimimise tasuvus.
Usaldusväärsuse, kasulikkuse ja nõuetele vastavuse kinnitus.
Iga 34 protsessi jaoks on sisestatud peamised tulemusnäitajad, mis näitavad, kui hästi IT-protsess oma funktsioone täidab ja eesmärkide saavutamisel. Need on põhinäitajad selle kohta, kui kaugele seatud eesmärke üldse võimalik saavutada, samuti head näitajad olemasolevate võimete, praktikate ja oskuste kohta.
Iga 34 IT-protsessi jaoks on määratletud kvalitatiivne skaala (0-5), mis näitab, millisel juhul tuleks protsess omistada teatud arengutaseme mudelile.
CobiTi raamatus "Auditeerimisjuhend" on iga 34 protsessi puhul määratud, kuidas hinnata selle vastavust kehtestatud nõuetele. Igaühe jaoks on määratletud:
1. Organisatsiooni isikud, keda tuleks auditi käigus intervjueerida.
2. Intervjueeritavatelt saadav teave ja dokumendid.
3. Hinnatavad tegurid (küsimustiku tüüp).
4. Testitavad (kontrollitavad) tegurid.
CobiT raamat Implementation Techniques räägib sellest, keda on vaja mõjutada COBITi juurutamiseks organisatsioonis, ja annab tegevuskava COBITi rakendamiseks. Ankeetküsitlused antakse juurutamisetapis kasutatavale personalile, ettevõtte IT juhtimise sisehindamiseks, sisejuhtimise diagnostikaks. Antakse auditi ja riskihindamise vormid.
Ettevõtete arusaamade muutumine IT-teenuste pakkumisel toob kaasa vajaduse juurutada nende kättesaadavuse haldamise protsess.
ITIL-i kolmandas versioonis käsitletakse IT-teenuste kättesaadavuse ja järjepidevuse haldamise protsesse koos (edaspidi protsess). Selle koostööprotsessi kõige olulisemad põhikontseptsioonid on:
kättesaadavus- IT-teenuse või selle komponentide võime teatud aja jooksul oma funktsioone täita;
usaldusväärsus- IT-teenuse või selle komponentide võime täita kindlaksmääratud funktsioone kindlaksmääratud töötingimustes;
taastatavus- IT-teenuse või selle komponentide võime taastada rikke tõttu osaliselt või täielikult kaotatud tööomadused;
hooldatavus- IT-komponentide omadus, mis määrab nende asukoha ja parameetrid, et tagada personali tegevuse ratsionaalsus paigaldamise, transportimise, hoolduse ja remondi ajal (see mõiste kehtib väliste IT-teenuste pakkujate kohta).
Ettevõttel on oma ettekujutus vajalike IT-teenuste kättesaadavusest ja maksumusest ning seetõttu on protsessi eesmärgiks tagada vajalik kättesaadavuse tase, säilitades samal ajal teatud kulutaseme. Selle eesmärgi saavutamiseks on protsessi eesmärk täita järgmised ülesanded:
IT-teenuste planeerimine ja arendamine, võttes arvesse äritegevuse nõudeid kättesaadavuse tasemele;
IT-teenuste kättesaadavuse optimeerimine kulutõhusate parenduste kaudu;
IT-teenuste kättesaadavust mõjutavate juhtumite arvu ja kestuse vähendamine.
Nende probleemide lahendamise käigus fikseeritakse ärinõuded IT-teenuste ja IT infrastruktuuri komponentide kättesaadavusele; koostatakse vajalikud aruanded; IT-teenuste kättesaadavuse taset vaadatakse perioodiliselt üle; koostatakse saadavuse plaan, mis määratleb prioriteedid ja kajastab meetmeid IT-teenuste kättesaadavuse parandamiseks. Teisisõnu, protsess taandub IT-teenuste osutamise planeerimisele, kättesaadavuse taseme mõõtmisele ja selle parandamiseks vajalike meetmete võtmisele.
Planeerimine
Planeerimisel sõnastatakse IT-teenuste kättesaadavuse ärinõuded, töötatakse välja IT-teenuste kättesaadavuse taseme ja vastuvõetava seisaku määramise kriteeriumid ning käsitletakse ka mõningaid infoturbe aspekte. Ettevõte peab kehtestama piiri, mis määratleb IT-teenuse kättesaadavuse ja mittekättesaadavuse, näiteks IT-teenuse lubatud seisakuajad IT-infrastruktuuri rikke korral.
IT-teenuste kättesaadavuse kujundamisel tehakse IT-taristu analüüs, et selgitada välja kõige haavatavamad komponendid, millel puudub liiasus ja mis võivad rikke korral avaldada negatiivset mõju teenuse osutamisele. IT-teenused. ITIL-i terminoloogias nimetatakse selliseid komponente Single Point of Failure (SPOF) ja nende määramiseks kasutatakse komponentide tõrke mõju analüüsi (CFIA) meetodit. Seda meetodit kasutatakse IT-komponentide rikete mõju hindamiseks ja prognoosimiseks IT-teenusele. CFIA peamised eesmärgid on:
Tehke kindlaks tõrkekohad, mis mõjutavad saadavust;
Komponentide rikke mõju ärile ja kasutajatele analüüs;
Komponentide ja personali suhete määramine;
Komponentide taastumisaja määramine;
Taastevalikute määratlemine ja dokumenteerimine.
Riskianalüüsiks kasutatakse riskianalüüsi ja -juhtimise meetodit (CCTA Risk Analysis and Management Method, CRAMM), mille käigus analüüsitakse IT komponentide võimalikke ohte ja sõltuvusi ning hinnatakse ebastandardsete olukordade või hädaolukordade esinemise tõenäosust. .
Nõutava käideldavustaseme tagamiseks on võimalik kasutada maskeerimistehnikaid negatiivse mõju eest, mis on tingitud komponendi planeeritud või planeerimata seisakutest, IT-komponentide dubleerimisest, aga ka komponendi jõudluse parandamise vahendite kasutamine. koormuse suurenemine jne. Juhtudel, kui konkreetsed ärifunktsioonid sõltuvad suurel määral IT-teenuste saadavusest ja seisakutest tulenevat firmaväärtust peetakse vastuvõetamatuks, seatakse teatud IT-teenustele kõrgemad saadavuse väärtused ja eraldatakse lisaressursse.
IT-teenuste pakkumise disain tagab, et esitatud käideldavusnõuded on täidetud, kuid see viitab IT-teenuste stabiilsele ja toimivale olekule. Võimalikud on aga ka tõrked, mistõttu planeeritakse ka IT-teenuste taastamist, sh korraldatakse interaktsiooni intsidentide haldamise protsessi ja Service Deski teenusega; seiresüsteemide kavandamine ja juurutamine rikete avastamiseks ja nendest õigeaegseks teavitamiseks; nõuete väljatöötamine riistvara, tarkvara ja andmete varundamiseks ja taastamiseks; varundus- ja taastamisstrateegia väljatöötamine; taastamise mõõdikute määratlus jne.
Teine planeerimise aspekt on seisakuaegade kindlaksmääramine. Kõik IT-komponendid peaksid alluma hooldusstrateegiale. Sõltuvalt kasutatavast IT-st ning konkreetse IT-komponendi poolt toetatavate ärifunktsioonide kriitilisusest ja tähtsusest võib teenuse sagedus ja tase erineda. Kui on vaja teenust osutada 24x7 režiimis, tuleb leida optimaalne tasakaal IT-komponentide teenindamise nõuete ja teenuse seisakutest tulenevate ärikahjude vahel. Heakskiidetud hooldusgraafikud tuleks dokumenteerida teenusetaseme lepingutes (SLA).
IT-teenuste kättesaadavuse parandamine
Miks parandada juurdepääsetavust? Põhjuseid võib olla palju: IT-teenuste kvaliteedi mittevastavus SLA nõuetele; ebastabiilsus IT-teenuste osutamisel; IT-teenuste kättesaadavuse langustrendid; lubamatult pikk taastumisaeg; ettevõtte taotlused kättesaadavuse taseme tõstmiseks.
Kättesaadavuse parandamine nõuab mõistlikku täiendavat rahalist kulu ning IT-teenuste täiustamise võimaluse kindlaksmääramiseks kasutatakse teatud meetodeid ja tehnoloogiaid, sh veapuu analüüsi (Fault Tree Analysis, FTA) ja süsteemi seisakuanalüüsi (Systems Outage Analysis, SOA).
Veapuu analüüs tuvastab sündmuste ahela, mis viib IT-komponendi või IT-teenuse rikkeni. Graafiliselt on rikkepuu (vt joonis) sündmuste jada, mis algab initsiatiivsündmusega, millele järgneb üks või mitu funktsionaalset sündmust ja lõpeb lõppolekuga. Sõltuvalt sündmustest võivad jadad loogiliselt hargneda.
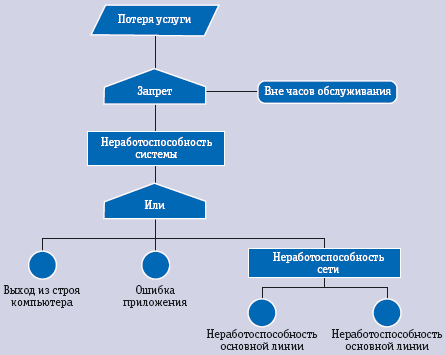
Süsteemi katkestuste analüüs on struktureeritud lähenemisviis IT-teenuste osutamise katkestuste algpõhjuste tuvastamiseks ja kasutab katkestuste asukoha ja põhjuste kindlaksmääramiseks mitut andmeallikat. Selle analüüsi eesmärgid on:
IT-teenuste osutamise rikete algpõhjuste väljaselgitamine;
IT-teenuse toe efektiivsuse määramine;
Aruannete koostamine;
Programmi algatamine aktsepteeritud soovituste rakendamiseks;
Süsteemi seisakuaja analüüsi abil saadud saadavuse täiustuste analüüs.
Süsteemi seisakuanalüüsi kasutamine parandab käideldavust ilma kulusid suurendamata, parandab töötajate enda oskusi ja võimeid, et vältida käideldavuse parandamise konsultatsioonikulusid ning määrab kindlaks konkreetse parendusprogrammi.
Teenuste kättesaadavuse parandamise tegevuse tulemuseks on pikaajaline plaan parandada IT-teenuste kättesaadavust ennetavalt rahaliste piirangute piires. Kättesaadavusplaanis on kirjeldatud olemasolevad ja kavandatavad kättesaadavuse tasemed ning tegevused, mida selle parandamiseks on vaja läbi viia. Plaani koostamine eeldab ettevõtete esindajate, juurutatud ITSM-protsesside juhtide, väliste IT-teenuse pakkujate esindajate, testimise ja hoolduse eest vastutavate tehnilise toe spetsialistide osalemist. Kava koostatakse perioodiks kuni kaks aastat ning järgmiseks kuueks kuuks peaks see sisaldama tegevuste üksikasjalikku kirjeldust. Plaan vaadatakse üle igas kvartalis minimaalsete muudatustega ja iga kuue kuu järel suuremate muudatuste tegemise võimalusega.
IT-teenuste kättesaadavuse mõõtmine
IT-teenust võib pidada kliendi seisukohast kättesaadavaks siis, kui seda kasutavad elutähtsad ärifunktsioonid toimivad normaalselt. Samas on peamisteks kvantitatiivseteks näitajateks saadavus - IT-komponendi reaalse saadavuse aja suhe teenusetaseme lepingutes määratletud saadavuse aega ning kättesaamatus (%) - käideldavuse inversioon. Neid parameetreid kasutavad IT-teenused ja need ei ole ärilisest vaatenurgast kuigi representatiivsed, kuna need ei kajasta ettevõtte või kasutaja saadavuse väärtusi – need võivad näidata IT-komponentide kõrget saadavust, samas kui tegelik saadavuse tase IT-teenustest jääb väheks.
Sellised näitajad nagu IT-teenuse katkestuste sagedus, katkestuse kogukestus, IT-teenuse katkemise mõjupiirkond võivad olla ettevõttele arusaadavad.
Rollid ja vastutused
Protsessi raames määratletakse protsessijuhi roll, kelle kohustuseks on protsessi juhtimine ja vajalike toimingute tegemine. Protsessi juht vastutab protsessi toimimise ja arendamise eest vastavalt määrustele ja plaanidele. Protsessijuhi rolli on soovitatav vastu võtta töötaja, kellel on praktiline protsessijuhtimise kogemus, ITSM-i tundmine, IT-s kasutatavad statistilised ja analüütilised meetodid, kulujuhtimise põhimõtted, personaliga töötamise kogemus, läbirääkimismeetodite omamine jne.
Protsessi rakendamine
Iga ITSM-i protsessi rakendamine on pikk ja keeruline projekt, millel on kindlad eesmärgid ja tähtajad. Ise juurutamine on keeruline: protsessi rakendamine paralleelselt igapäevatoimingutega ei võimalda täielikult projektile keskenduda; ressursside pidev "tõmbamine" projektiga seotud kõrvaliste ülesannete täitmiseks toob lõppkokkuvõttes kaasa rahaliste kulude suurenemise, projekti ajastamise määramata aja nihutamise, järkjärgulise tähelepanu kadumise või isegi võimaliku tegevuse peatamise. projekt. Lisaks nõuab ettevõttesisene juurutamine valdkonnateadmisi, millega kaasneb kulukas koolitus.
Nagu iga projekt, algab protsesside elluviimine projektimeeskondade loomisest, projektijuhtimise dokumentide väljatöötamisest, projektiplaani koostamisest jne. "Projektieelse" töö etapis viiakse läbi turundustegevusi, et tutvustada ettevõtete esindajaid ITIL-i tehnoloogiate ja soovitustega ning põhjendada ettevõtte vajadust IT-teenuste kättesaadavuse juhtimise protsessi rakendamiseks.
Pärast protsessi elluviimise kohta kokkuleppimist ja positiivse vastuse saamist määratakse kindlaks protsessi teemavaldkonna eesmärgid ja piirid.
Mõju ja probleemid
Protsessi juurutamise peamine mõju seisneb selles, et IT-teenused on kavandatud kättesaadavust silmas pidades ning neid juhitakse ja hallatakse kokkulepitud kättesaadavuse tasemel ja kindlaksmääratud kulude piires. Positiivsed tegurid on ka: ühe IT-teenuste kättesaadavuse eest vastutava isiku olemasolu; IT-infrastruktuuri jõudluse optimaalne kasutamine, et tagada IT-teenuste kättesaadavuse nõutav tase; IT-teenuste rikete sageduse ja kestuse vähendamine aja jooksul; IT-teenuse pakkujate tegevuse kvalitatiivne üleminek teenuste osutamisel esinevate vigade kõrvaldamiselt nende kättesaadavuse taseme tõstmisele.
Võimalikud probleemid, mis võivad protsessi rakendamise ja toimimise otsust negatiivselt mõjutada, on tavaliselt organisatsioonilist laadi:
Olukorra olemasolu, kus iga IT-juht vastutab oma vastutusel olevate IT-süsteemide või komponentide saadavuse eest, samas kui IT-teenuste üldist saadavust ei jälgita ja see võib olla mitterahuldav;
Protsessi rakendamata jätmine, kuna IT-teenuste praegust kättesaadavust peetakse vastuvõetavaks;
Eeldused, et kui on muid juurutatud ITSM-protsesse, teostatakse saadavuse haldusprotsess automaatselt;
Vastupidavus IT infrastruktuuri haldamise tsentraliseerimisele IT-juhtide poolt;
Protsessijuhi ebapiisav volitus, mis viib suutmatuseni ülesandeid korralikult täita.
Jevgeni Bulõtšev ( [e-postiga kaitstud]) - I-Teco ärikonsultatsioonide osakonna konsultant (Moskva).


